The Fede Engineering & Leadership Handbook
What is this?
I have terrible memory, so I make it a habit to jot down everything. This includes ideas I want to explore, I ideas I’ve validated and can’t afford to forget, and insightful concepts, explanations, and nuggets of wisdom I’ve come across from people smarter than myself. I then diligently store all this information in a searchable format. Instead of trying to boost my memory recall, I rely on the trusty Ctrl/Cmd + F shortcut to quickly find what I’m looking for. However, over the past 12 years, I’ve scattered these notes across numerous platforms and applications, forcing me to become my own makeshift SQL expert, performing manual JOIN operations to locate what I need.
The goal of this handbook is to act as a living document that keeps me honest and organized by forcing me to continue to update it in one accessible location. Also, I figured that if it helps me, it might just be useful for someone else too.
Effective Organization
A software engineering organization, in its simplest definition, represents a collective of software engineers assembled and coordinated to deliver valuable, functional solutions for a shared purpose. Constructing software engineering solutions is intricate, but the exercise of organizing humans to achieve a common is an even greater challenge. This challenge becomes even more complex with the growth of the team in the pursuit more ambitious objectives. The effective organization is the one that successfully manages to pull off this intricate orchestration at every stage during its existence.
An effective organization is like an explorer ship:
- Has a North Star that illuminates a distinct and clear purpose.
- Operates with an unyielding set of values and guiding principles to survive rough waters.
- Leverages a strategy as a map, which updates along its journey.
- Defines and follows policies, processes, and structures that support their quest.
- Continuously measures and verifies their position in their journey.
- Uses tools on every aspect of their voyage, from navigation to preventing mutiny.
In more traditional corporate language, an organization must have:
- Mision: What it does
- Vision: What it aspires
- Purpose: Why it does it
- Values: How it does it (philosophically)
- Strategy: The plan to achieve it
- Processes: How it does it (operationally)
- Policies: Rules to follow there
- Structures: How it organizes itself
- Tools: What it does it with
- Introspection: How it measures it is on the right track
Mission, Vision, and Purpose
Mission, vision, and purpose are three important concepts that define an organization. They are often used interchangeably, but they have subtle differences.
Mission is what the organization does and whom it serves. It is the organization’s reason for being.
Vision is what the organization wants to achieve in the future. It is a long-term goal that inspires and motivates the organization.
Purpose is why the organization exists. It is the organization’s core values and beliefs. It is what drives the organization to achieve its mission and vision.
Values
Every company has a distinct set of values, some are lengthy, others make great acronyms. What is imperative is that they are not just empty inspirational quotes on an “About Us” page. They should be your indivisible set of axioms from which you and the rest of the organization derives solutions to situations it has never seen before.
To see this in action, if one of your values is “winning is everything”, then you can expect behaviors that go outside the rules. Conversely, if “sustainability” is one of your core principles, then in situations like when deciding between two cloud providers you might choose the one with the smallest carbon footprint.
The following are the 8 values that I align with written in different styles. First column is mine, the others are rewrites courtesy of ChatGPT.
| Fede Style | Formal | Casual | Edgy |
|---|---|---|---|
| Never the Expert, Always the Student | Learning Mindset | Keep Learning Forever | Never Stop Fucking Learning |
| If it’s not a “Fuck Yes”, it’s a “Fuck No” | Empathy and Passion | Give a Damn | Give a Shit, Feel Passion |
| Discipline, Dedication, and Rigor | Dedication and Discipline | Stick to Your Guns | Discipline Like a Badass |
| Better in a Team than Solo | Teamwork and Growth | Teamwork Makes the Dream Work | Win Together |
| Comfortable with being Uncomfortable | Vulnerability and Humility | Stay Real and Humble | Embrace Vulnerability, Be Fucking Humble |
| Figure It Out | Resourcefulness and Tenacity | Get Creative and Never Quit | Get Shit Done, No Excuses |
| Good Enough, Never Perfect | Bias for Action | Just Get It Done | Relentless AF, Keep Going |
| Responsible Capitalism | Responsible Capitalism | Responsible Capitalism | Responsible Capitalism |
Strategy
“Engineering strategy is the discipline of making decisions about how to best use engineering resources to achieve a particular set of goals.” - Will Larson, Google Staff Engineer
A strategy is a roadmap for how the organization will achieve its goals, making the best use of its technical capabilities and taking into account its resources, and the competitive landscape.
A lasting strategy (e.g.: one that is not re-written every quarter) should be developed according to the following factors and in this order:
- Data
- Evidence
- Precedent
- Argument
- Instinct
Reviewing and updating your organization’s mission, vision, and strategy should be an ongoing process. You should regularly review them to make sure that they are still aligned with the needs of your organization and your stakeholders. The cadence will depend on the size and complexity of your organization and the industry that you serve. Typical cadence for software engineering organizations is 1 to 3 years.
Best Practices:
- Shouldn’t require mandating. Successful ideas spread.
- Should feel they were chosen because they were the best option.
- Should generate excitement.
- Should be defined around activities that influence results.
Results Based Management (RBM) is a management approach that focuses on achieving results rather than just following processes. It’s like aiming for the finish line instead of just running around the track. With RBM, you set clear goals, measure your progress, and make adjustments as needed to ensure you’re on track to achieve those goals. It’s all about getting things done and making a real impact.
- Outputs: What the organization puts out.
- Outcomes: The effect the output causes on consumers.
- Impact: The effect the outcome causes on our goals.
“Results-based management is the only way to run a successful software company. We need to focus on delivering value to our customers, not just following processes.” - Bill Gates, former CEO of Microsoft
Staging
Recognizing the right time for the right actions is crucial for achieving success. You might have all the right elements—people, tools, strategies—but if they aren’t utilized appropriately for the stage you’re in, it can lead to catastrophic results. The Saturn V rocket (so far the only vehicle to carry humans beyond Low Earth Orbit) had 3 distinct stages in its launch procedure. Had all stages fired simultaneously, we wouldn’t have been able to put 24 astronauts on the moon.
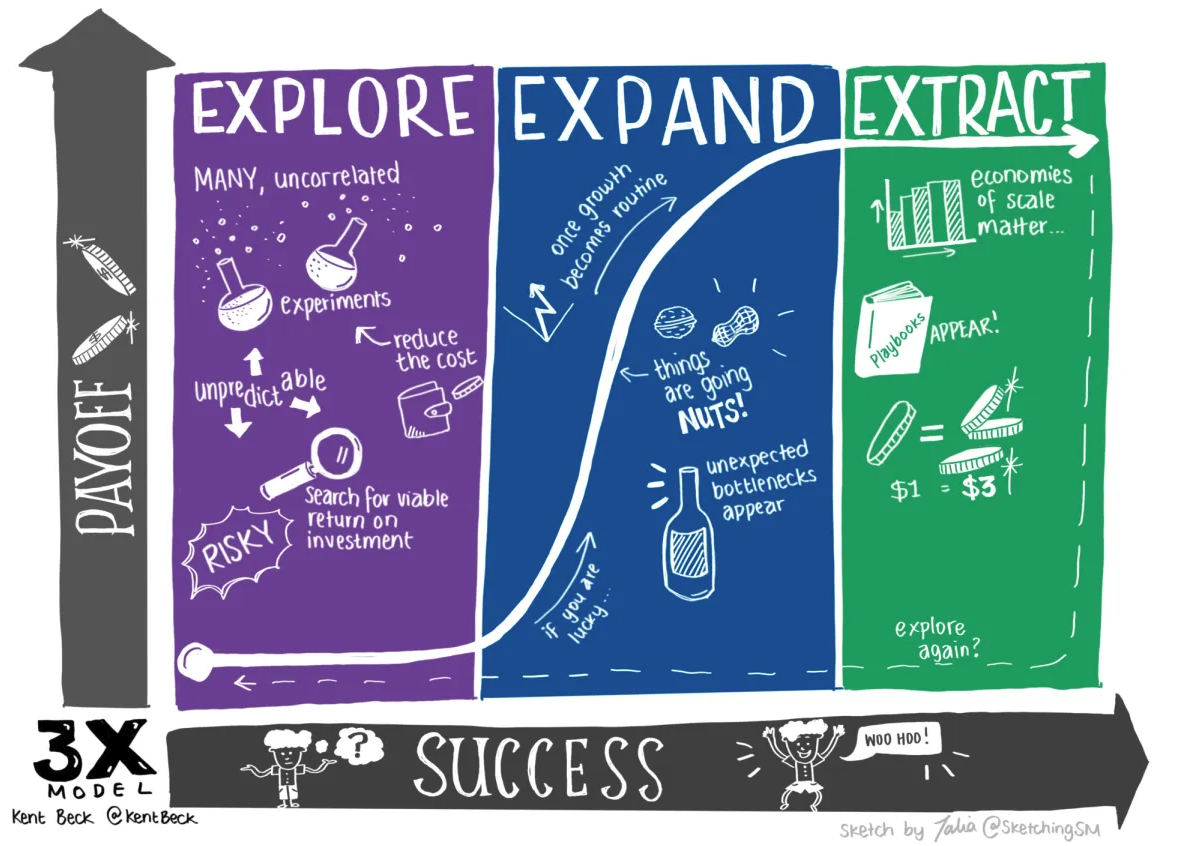
To achieve success, your actions and behaviors must align with the specific stage you find yourself in. Kent Beck’s 3X Model provides a practical framework for experimenting and innovating, breaking down the complex journey of “Product Develpment Triathlon” into three distinct stages:
Explore
- Tools: Iteration, testing, and experimentation.
- Environment: Uncertain, but adaptable
- Enemy: Risk.
- Goal: Disrupt inertia, combat disinterest, and discover a market fit.
- Activities: Maintain minimal costs, be cautious of local maxima (experiment success that won’t scale), and make choices that minimize the risk of change. Prioritize high iteration speed, low infrastructure costs, and flexibility for pivoting or scaling.
Expand
- Tools: Discipline and measurements.
- Environment: Awkward, but experiencing growth.
- Enemy: Bottlenecks.
- Goal: Identify the key rate-limiting resource, design structures and processes that will allow it to scale.
- Activities: Seek sustainable growth and early proof on how you could optimize without fully commiting. Remove blockages, solve infrastructure challenges. In case you applied Paul Graham’s “Do Things that Don’t Scale” during the “Explore” stage, figure out how to achieve the same results with actions that do scale.
Extract
- Tools: Specialization, and optimization.
- Environment: Stable, but change is risky.
- Enemy: Inefficiency.
- Goal: Fine-tune your system without compromising quality.
- Activities: Optimize your “Replicators” to achieve maximum output with minimal input. Focus on cost reduction, margin expansion, and the application of economies of scale, to deliver your product or service at peak efficiency (low cost, high quality).
Navigating this triathlon, or any triathlon for that matter, presents a unique challenge. Each phase demands its own set of tools, expertise, and measurement systems. A bicycle won’t serve you well in the water, becoming a faster runner doesn’t automatically make you a faster swimmer, and the way you measure progress shifts from miles per hour on a bike to seconds per 100 meters in the water. Moreover, these phases are distinct and don’t overlap; just as you wouldn’t attempt to swim with running shoes, the critical moments occur at the end and beginning of each phase as you establish your rhythm and during the transitions between them.
In the context of an engineering organization,failure to recognize which stage your idea, product, organization is at can be disastrous. Furthermore, you can have success in one stage to then fail categorically on another one. Particularly in the context of people. Is the same team supposed to transition throughout all phases? If so, you better focus on hiring triathlonists. Or can you move along the product and specialize three distinct teams of Explorers, Expanders, and Extracters?
 Kent Beck’s 3X visualized by Talia @sketchimgSM
Kent Beck’s 3X visualized by Talia @sketchimgSM
Goals
Having the appropriate goals that align with the scope, context, and stage can motivate a team to incredible success. Conversely, misaligned and overly ambitious goals lead to frustrating conflicts and failures. Several popular acronymized frameworks aim to help with setting, tracking, and achieving goals:
- SMART: Specific, Measurable, Achievable, Relevant, and Time-bound. It emphasizes setting goals that are clear, quantifiable, realistic, and time-constrained.
- OKR: Objectives and Key Results
- BHAG: Big Hairy Audacious Goals from “Built to Last” by Jim Collins
- 4DX: 4 Disciplines of Execution by Covey, the author of “7 Habits of Highly Effective People”
- GSM: Goals, Signals, and Metrics from Google
While these frameworks are valuable tools, a great tool for the wrong job builds nothing. A goal can be an ambitious vision, a clear mission, a focused business objective, and even a specific target. They all share a common element: a definition of “done” or “success.” To understand the nuances, it helps to analyze the scope of the goal, whether it’s a grand aspiration or a specific task.
Dustin Moskovitz, founder of Asana, leaders in work management, created the “Pyramid of Clarity” as their way of decomposing goals:
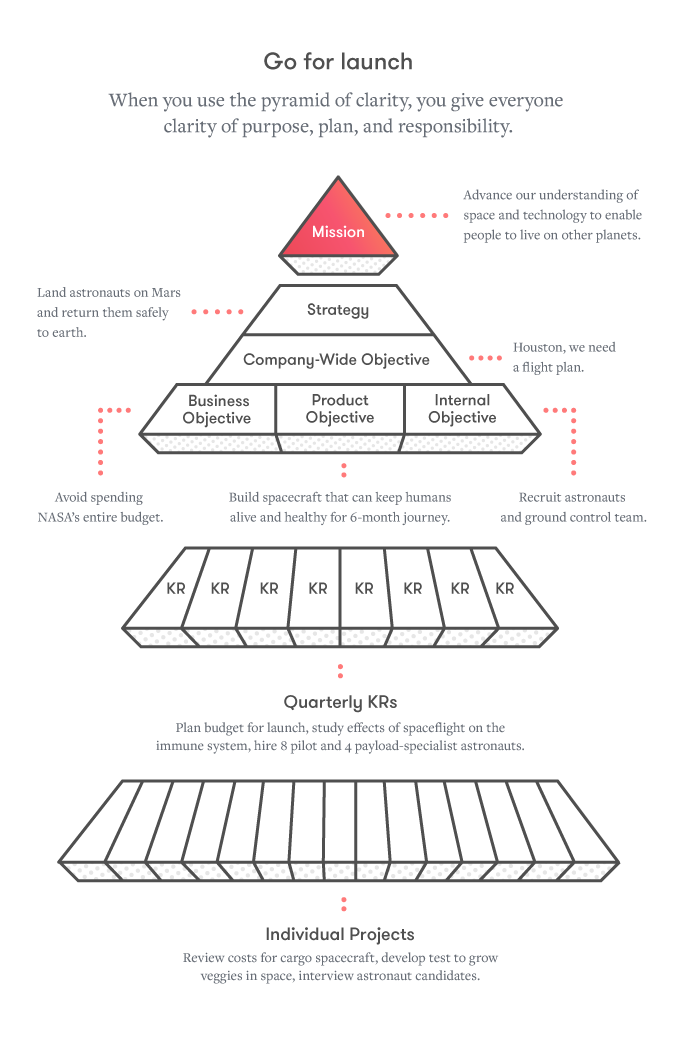 https://wavelength.asana.com/pyramid-clarity-strategic-alignment/
https://wavelength.asana.com/pyramid-clarity-strategic-alignment/
The mix of terminologies surrounding this subject can get confusing: goals, objectives, deliverables, targets, results, measurables, and metrics. However, not all of these terms are interchangeable or share the same characteristics. In fact, some of them can exhibit varying properties based on the specific context in which they are used. What they all have in common is that they offer a definition of ‘done’ or ‘success.’ So, how can we break this down? What exactly are you measuring and tracking? Is the goal the entity you’re directly tracking, or is it a breakdown of measurable targets that collectively lead to achieving the goal? If it’s the latter, how can you ensure that you are measuring the right metrics to progress toward the goal?
This is a table I created a long time ago to help me work through the terminology:
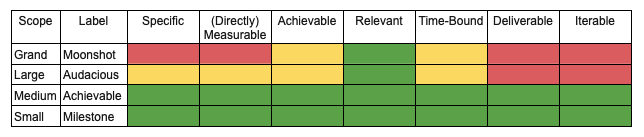
This decomposition extends the SMART model to analyze various types of goals. Technically, every goal is measurable in the sense that it should have a defined criterion for success. However, the term ‘directly measurable’ implies a different level of clarity. Let’s consider the distinction between having a broad goal like ‘being healthy’ and a more specific one like ‘maintaining a body temperature of 99°F for 99% of the year.’ Furthermore, the ability to control or deliver a goal distinguishes it from being an objective or a target. While you can’t directly control your body temperature, you can control how often you work out or manage your calorie intake during the week.
The following is my adaptation of Google’s GSM process with OKRs for creating “Nested OKRs” or “MOKRs” (Moonshot OKRs). I’ve found this approach to be highly effective for consistently developing , as it helps guard against the ‘streetlight effect’ of only focusing on what’s immediately visible, thereby reducing the risk of setting misaligned goals and unattainable targets:
- Goal: This represents the desired outcome, typically at a high level and devoid of technical specifics.
- Signal: These are the objectives you’d like to measure, although you can’t directly control them.
- (Actionable) Targets: These are the specific deliverables you can both measure and directly influence.
This model enables you to quickly assess whether you’re on the right track and, if not, why you might be falling short. Your “Actionable Targets” should be executed in parallel and break down into deliverable milestones. They should be designed such that, based on a set of validated assumptions, each has the capacity to drive the signal in the desired direction.
Ideally, the “Signals” should be monitored in real-time as the “Actionable Targets” are being achieved. This enables you to simultaneously validate if these deliverables are moving you closer to your “Goal”. If the “Signals” aren’t heading in the right direction despite hitting your targets, it suggests that the assumptions behind your defined deliverables may have been incorrect or improperly implemented. The latter can sometimes result from failing to include paired indicators that avoid unintended negative consequences on the overall “Goal” and its associated “Signals”. For instance, if your “Goal” is to reduce losses due to fraud, it may lead you to treat everyone in your checkout flow as a potential fraudulent agent. This approach should aligned with other “Actionable Targets” such as false-positive rate and customer satisfaction scores.
Putting it all together, here is a simplified example from a startup I co-founded:
Moonshot Goal: Become the #1 ready-made meal delivery service in Austin, TX.
Audacious Goals/Objectives/Signals:
- Increase website first-time conversion rates from 5% to 30% within 2 years.
Achievable Goals/Key Results/Actionable Targets:- Achieve less than 1% checkout flow error rate within 12 months.
- Reach less than 200ms response time for all pages within 10 months.
- Implement A/B testing to optimize site layout and iterate until achieving drop-rates below 20% within 6 months.
- Achieve delivery efficiency of less than 1% late deliveries within 1 year.
Achievable Goals/Key Results/Actionable Targets:- Build a delivery clustering algorithm that keeps all deliveries within 5 minutes of each other within 12 months.
- Perform inspections of 90% of the delivery fleet every quarter
- Achieve customer retention rates of 80% in within 1 year.
Achievable Goals/Key Results/Actionable Targets:- Launch subscription billing model within 12 months.
- Identify and address outliers in dish feedback from the weekly customer survey, to reach less than 10% of dishes with a z-score exceeding 1.5 standard deviations from the mean mention rate within 8 months.
- Mantain employee churn below 5%.
Achievable Goals/Key Results/Actionable Targets:- Conduct quarterly engagement surveys with a minimum 85% response rate.
Note that even the Actionable Targets can be further decomposed into milestones. These are usually the implementation details of each team responsible with each target.
Effective Growth
Companies, divisions, departments, all operate an exists on a transient state. The organization that resists change, or doesn’t seek it, is one that at best, is not destined for greatness, and at worst doomed to failed sooner rather than later. Constant evolution and change is literally baked into the fabric of our reality (2nd Law of Thermodynamics). However, unbounded growth is cancer. It is in the transition between one stage to another where an organization is most at risk of introducing cracks in its foundations. The key characteristic of any successful enterprise is the effective handling of its growth and scaling journey.
“The efficient organization has sub-linear resource cost growth as it increases in scale.”
Unfortunately, the answers to this problem are very specific to each organization. Yet, there are a number of practices that if implemented correctly, can unlock teams and leaders to scale effectively:
- Satisficing
- Aligning
- Auditing
- Incentivizing
- Knowledge Sharing
- Async-ness
- Heuristic-Driven Values (Policies) / Value-Aligned Heuristics
- Growth-Focused Processes
Satisficing
Getting distracted is not just procrastinating on social media, it’s losing focus on your main quest and chasing side ones. This can mainly happen due to two behaviors:
- Not measuring the correct thing.
- Not being comfortable with saying “good enough”.
 https://modelthinkers.com/mental-model/satisficing
https://modelthinkers.com/mental-model/satisficing
Switching from being a Maximiser to Satisficer can be very difficult. Here’s a useful practice: Go running with one shoe slightly untied. It can feel uncomfortable but if your pace is not affected by it, don’t stop. Your goal is to complete your run in the shortest time possible, stopping in this case is guaranteed to affect that goal negatively, the only purpose of this action is to reduce your uncomfortability. The requirement is to mantain a specific pace, if you have satisfied that goal then don’t try to maximize.
Aligning
The practice of “aligning” is a fundamental concept in ensuring that actions, behaviors, and decisions within an organization are in harmony with its goals, values, and the broader context. This practice is essential for maintaining cohesion and preventing potential conflicts.
Alignment involves several key elements:
- In Service of Current Goals: Actions should contribute to achieving the organization’s current objectives.
- Embodying Values: Decisions and behaviors should reflect the core values of the organization.
- Avoiding Conflict: Alignment seeks to prevent conflicts or contradictions with other teams or departments.
- Facilitating Future Decisions: Actions should be forward-thinking, contributing to the organization’s adaptability and future readiness.
This practice can take many shapes depending on the situation. Here are a couple examples:
When defining team goals and metrics: Imagine an e-commerce platform with a team responsible for the Billing process. If they define the team’s goals to be around story points, velocity, or the number of features, they will get teams focused on churning out code without regard for quality, customer satisfaction, or collaboration. They will maximize metrics they are being measured against. Instead, consider if, in the case of that Billing team, some of their metrics were: dollars unrealized during the checkout experience and customer support calls regarding issues in the billing process. Now, this team is aligned to maximize quality and customer satisfaction. It’s not about code for the sake of code, but about what features or optimizations will streamline the checkout process in such a way that more purchases are completed (fewer bugs, less friction in the funnel) and in a way that leaves customers happy and satisfied (fewer frustrated calls).
When defining organizational policies: An engineering department may establish a minimum code coverage requirement. At a simple glance, it’s a policy to motivate and incentivize quality through the quantity of testing. However, it disregards the quality of the testing and the impact that maximizing this one metric could have on the time to complete testing and deploy code. This policy is missing alignment with the complete goals for the department, namely deploy time. Conversely, if the policy focuses on “efficient, high-quality testing,” it could track the rate of bugs reported in production alongside the time to complete a deploy. This empowers engineers to keep only a specific suite of high-signaling-error-rate tests. It also opens the door to creative solutions to the problem, perhaps with parallel running of tests. However, this would likely have an impact on infrastructure costs, presenting another opportunity to enhance alignment if there is a tight budget.
The important consideration is that there’s no one perfect solution in the practice of aligning. The critical factor is always to consider the breadth, scope, lateral impact, and the potential unintended consequences now and in the future.
Incentivizing
Aligning your incentive structures and recognition methods with your desired outcomes and values is another crucial activity. It’s essential to ensure they do not center around vanity metrics that can be manipulated and bring no tangible value to the business, customers, teams, or individuals.
For instance, if recognition is exclusively tied to outcomes, it can foster an organizational culture lacking in boldness, creativity, and innovation. However, recognizing both successes and failures resulting from ambitious attempts at lofty goals helps cultivate a culture that appreciates both risk-taking and resilience.
Incentives can inadvertently promote individualism, so it’s vital to use them as tools for fostering a culture where individuals support each other’s success and don’t let each other fail.
It’s critical not to reward relationships. If people perceive that advancement in your organization is primarily determined by who they know, it can lead to a culture of bloated calendars and meetings, suck-ups, and vanity metric reporters.
Recognize and reward both outcomes and efforts. Neglecting to acknowledge efforts can lead to team burnout. Keep in mind that efforts and results are interrelated, and recognizing both helps maintain a balanced and motivated workforce.
Moreover, don’t rely solely on extrinsic motivators. Instead, remove barriers and provide opportunities for individuals to self-motivate with the three intrinsic motivators:
- Mastery: The desire to improve and excel.
- Autonomy: The desire for independence and self-direction.
- Purpose: The desire to contribute to a greater cause.
Consider these examples:
Hackathons: Conduct them yearly or quarterly, where individuals or teams can work on projects they’re passionate about and present them to the organization. These projects might even lead to new products or features.
Open Source Contributions: Encourage contributions to open source tools used by the organization or release internally developed tools as open source projects. Note that maintaining open source projects comes with responsibilities.
Peer-to-Peer Celebrations: Implement a system for employees to nominate or recognize their peers, either anonymously or not. Can be in real time or tallied across a Sprint and those with the most votes are highlighted during Sprint kick-offs.
Audits
The most common reason as to why we do something in a certain way, is because we have always done it like that. What’s more, circumstances and contexts change over time but we don’t adjust accordingly. Inertia is the root of a lot of inefficiencies. To combat it, routinely audit people and organizational activities. It’s a simple process of asking certain questions or taking a step back to review if there have been some inefficiencies creeping slowly over time.
Some areas to audit regularly:
Calendar
- Are you context-switching too much?
- Action: Group 1:1s together in one day
- What is 80% of your calendar going towards?
- Action: Should be spent towards your top 20% goals
- Are you having to work after hours to be able to focus?
- Action: Block-off time for important but not urgent work
- Are you maintaining a good work-life balance?
- Action: Mark your working hours and do not reach out to others outside of theirs. Lead by example.
Meetings
« TODO! »
Types of meeting based on their : To motivate/inspire/celebrate To share knowledge/broadcast: Info not everyone will open in an email To brainstorm: To make a decision Must have a written proposal first. Only when async is too inefficient To sync/agile
Energy
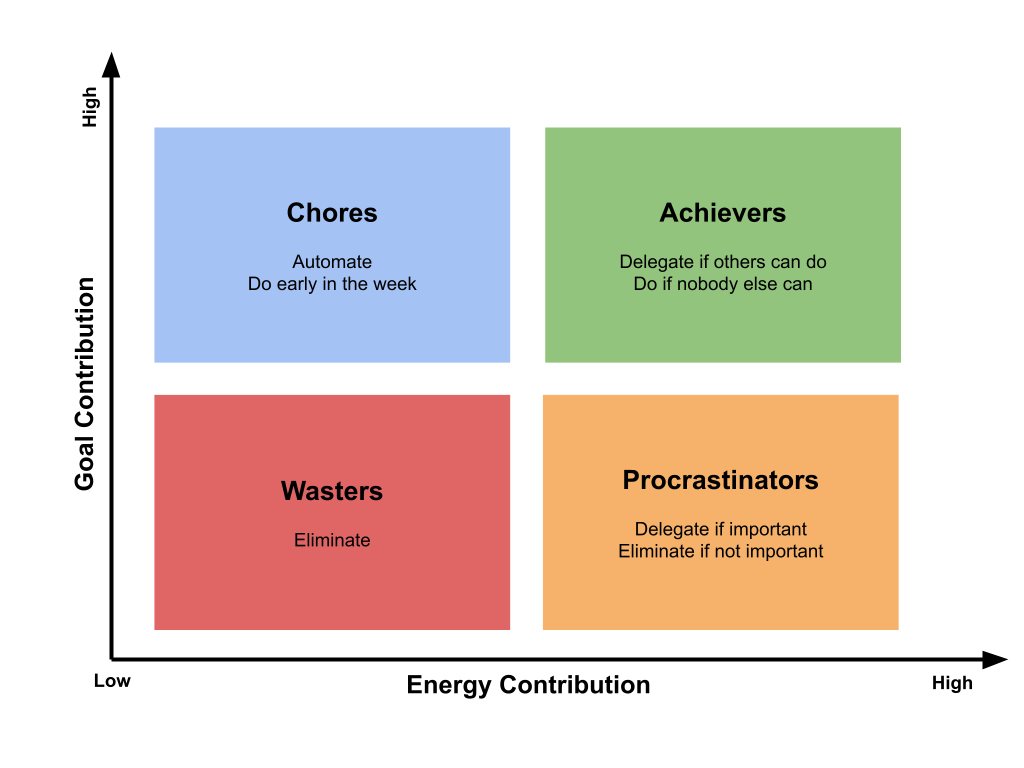
Evaluate all your activities and divide them into:
- How much energy they give or take
- How much they contribute to goals
You will find they can be grouped in four main categories:
- Wasters: If they make you feel drained and provide little to no value towards goals.
- Action: Eliminate
- Procrastinators: They make you feel energized but provide little to no value towards goals:
- Action: Delegate if they are important. Eliminate if not important
- Chores: They make you feel drained but contribute towards goals:
- Action: Automate if possible. Do early in the week if not
- Achievers: They make you feel energized and contribute towards goals.
- Action: Since these are the most enjoyable and impactful to you, likely they will also be for others, delegate them if possible to embody a servant and growth-minded leadership. If nobody else can do them, then schedule them for later in the week.
Self-Organization
Set yourself a good system for managing your workload and getting things done. Consider the following Kanban implementation of the Getting Things Done (GTD) model:
Collect The first column in your board should always be “To Classify”.This is your inbox of ideas, of actions, of reminders. Don’t filter.
- Process Before you start every week and at the end of every day, you will go through your “To Classify” column and determine a course of action:
- If not towards an immediate goal:
- Mark it as “Future”
- If useless:
- Mark it as “Trash” and keep notes as to why
- If a “you” task:
- If you can get it done immediately, do so and mark it “Done”
- Otherwise, assign it to the respective goal with priority and deadline/date
- If a “delegate” task:
- If you can delegate immediately, do so and mark it “Done” or “Follow Up”
- Otherwise, assign it to the respective goal with priority and deadline/date
- If not towards an immediate goal:
Follow Through This is the most important step! It’s where you actually take action on the items on your lists.
- Repeat Do it every week.
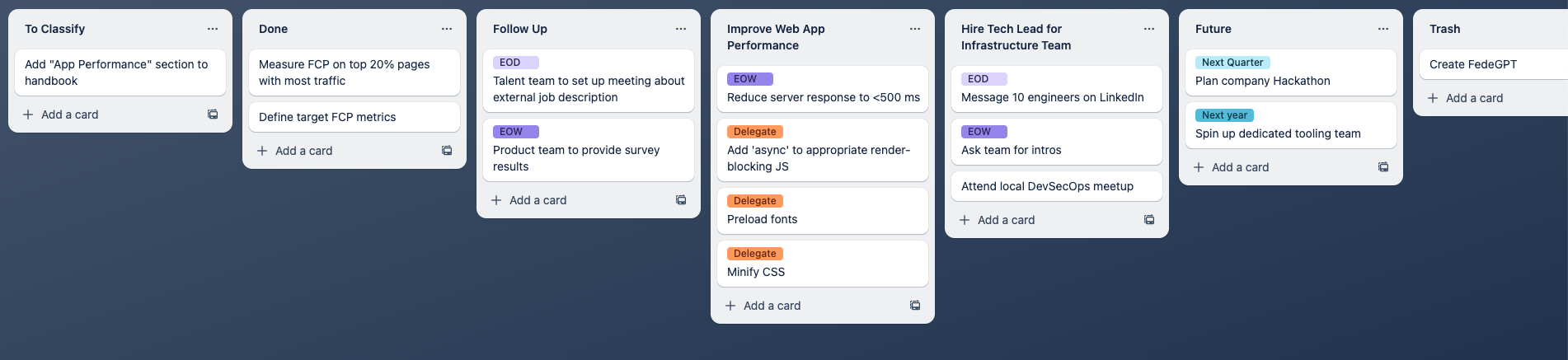 Example using Trello
Example using Trello
Decisions
Some best practices:
For every major decision, create a document recording the circumstances, inputs, analysis, and all considered options. Review this document if any of the circumstances and inputs change down the road.
Should always be made at the lowest level possible.
Making them doesn’t require the most senior, it requires the most knowledgeable.
Teams constantly slowed by decision-making are indicators of:
- Unclear objectives
- Unclear strategy
- No confidence and people want the burden on someone else
Async-ness
One of the main tools to effectively navigate either the fully remote or hybrid mode of working that is without a doubt the way of the future, is to instill healthy asynchronous practices. What this means is adding an extra consideration before initializing any activity or process that requires people to interact: “How can this be done asynchronously?”. For example:
Instead of immediately scheduling a meeting to discuss a potential decision, consider, “Can this be handled in a live document?” or “Can we at least get started in a live, online document and have a shorter more efficient meeting later?” Instead of locking an entire team in a stand-up because everyone is waiting for their turn to ask a question, consider “Can I post my question in the group Slack channel and someone can answer when they have time?”
An even greater consideration that organizations need to be clear on is, do you operate in a “follow the sun” model or a “universal timezone” one? With follow the sun, functions and teams are organized around their physical proximity, allowing them to work within normal working hours. Conversely, a universal timezone approach requires everyone, no matter where they are, to work during a certain timerange, usually around the timezone of the main offices. There are pros and cons for either. What’s important is making sure it is decided and that everyone has buy-in.
Knowledge Sharing
In an engineering organization, knowledge is the most valuable yet intangible asset. Therefore, the organization must cultivate a culture, establish processes, and implement policies that facilitate the recording, updating, and sharing of knowledge to enable scalability. Otherwise, this invaluable asset may be lost.
“Knowledge is viral. Experts are carriers.”
Knowledge sharing is one of the most scalable activities when we consider the time spent creating and maintaining knowledge versus the cumulative time saved when others read and utilize it.
To achieve this, it is imperative to build a self-reinforcing loop of knowledge. An organization should encourage experts to record and distribute their knowledge. Simultaneously, leaders play a pivotal role by creating rituals, mechanisms, and incentives that promote knowledge recording and distribution. These efforts result in the growth of more experts and leaders who value knowledge sharing.
Some of the common challenges to creating an effective culture:
Lack of Psychological Safety: Many engineers may feel inadequate or unqualified to openly share with others. The risk of being ridiculed if there’s a gap or mistake in knowledge can be a powerful agent holding them back.
Fragmentation: Information scattered across various platforms can lead to inefficiencies.
Mimicry: Some individuals may copy patterns without a deep understanding, leading to knowledge gaps.
Graveyards: Inactive areas of knowledge that hold little interest for the team.
Knowledge can be distributed through different means:
- Personalized: Tailored one-on-one or through mentorship.
- Documented: Asynchronous, reaching many through documents and videos.
- Professorial: Synchronous, educating a broader audience.
Each type has its trade-offs, such as personalization vs. generalization, scalability vs. maintainability, and conciseness vs. brevity.
Recorded knowledge, such as documentation, is a cornerstone for remote work. Highly organized, indexed, and searchable documentation is vital for high productivity, while continually evolving documentation is key to successful scaling.
Furthermore, recorded knowledge can come not just from formal writeups, but even by being intentional to do so within normal informal activities:
- A policy to enforce using public Slack channels as much as possible. GitLab goes as far as having a dedicated metric tracking how many DMs are sent in private channels.
- BCC’ing external communications to a team’s email list so everyone can stay informed.
- A process to clear Slack channels every month or so to ensure people keep the organization’s knowledge base updated.
Heuristics
These can range from well defined guidelines that dictate how certain procedures should be carried out (e.g.: escalation policies, HR policies), to more abstract heuristics that embody living examples of the company values (e.g. “open door policy”).
Many an organization proudly display and boast their values externally and internally, yet does nothing tangible to apply them. This is where company sanctioned heuristics (or policies) come into the fold. Here’s a shortened version of the definition from Wikipedia:
“Any approach to problem solving or self-discovery that employs a practical method that is not guaranteed to be optimal, perfect, or rational, but is nevertheless sufficient for reaching an immediate, or approximation in a search space. Heuristics can be mental shortcuts that ease the cognitive load of making a decision.”
Simple and concise company-sanctioned heuristics make your day just that much easier. Research shows that we have a finite amount of decisions we can make per day, going beyond that and our judgement in making further decisions declines. This policy-driven approach saves you time and cognitive power. When faced with situations that fit the bill, don’t have think about it, just follow the company policy.
As you can see, this follows from the “sufficing” practice, but it can also follow the “aligning” practice. Each of your heuristics should correspond to one or more of your defined values.
| Value | Heuristics |
|---|---|
| Learning Mindset | “If there’s something you don’t like doing, become the best at that thing” |
| Care Deeply | “If you are going to do it, do it to the best of your abilities” “If you liked it, you should’ve written a test for it” |
| Dedication and Discipline | “Hope is not a strategy” |
| Teamwork and Growth | “Always assume good intent” |
| Vulnerability and Humility | “No blame” “Sunlight is the best disinfectant” |
| Resourcefulness and Tenacity | “Failure is welcomed if you learn from it” |
| Bias for Action | “Always ask for help, but you better have attempted something first” |
| Responsible Capitalism | “All else being equal, choose different over the same” |
Effective Hiring
“I am convinced that nothing we do is more important than hiring and developing people. At the end of the day you bet on people, not on strategies.” - Lawrence Bossidy, former Chief Executive of General Electric and Honeywell
It starts here. An organization’s number one asset is its people. Products pivot, strategies evolve, code can get sudo rm -rf‘d, names and logos can be changed. However, people are what make a company. The right people not only lead to success, but they make the journey a lot more enjoyable. Whereas the wrong people can not just make the journey slow and painful, they can outright stop it.
Unfortunately, the size of a workforce and the perception that a company is constantly hiring have become vanity metrics for success. This couldn’t be further from the truth. In fact, your effectiveness as a leader is measured by your ability to leverage and achieve more with less. An organization is a system of people working together to achieve a shared goal. They are not being hired to work in silos, therefore, consider the combinatorial explosion of adding a new person into your system. The number of unique possible connections in a network of n people can be calculated with n(n-1)/2. The complexity and costs in communication grow polynomially (quadratically with respect to n). This is a bit of an oversimplification because every person added is not talking to every other person in an organization. Still, the point to consider is: Only if the value-added greatly surpasses the increase in internal complexity, should you consider hiring.
Henry Ward, CEO and co-founder of Carta wrote a great one-pager on hiring, and his first principle is: “Hiring means we failed to execute and need help”.
Now that the gravity and importance of hiring have been stated, how do you hire? What does “the right people” mean? Who are they? How do you find and identify them? How do you bring them into your company? And how do you grow them so they continue being “the right people?” The answers to these questions is the hiring process.
General Guidelines
Hire for value fit over culture Cultures evolve (or should), values don’t (or shouldn’t). Alignment on a north star is achieved through shared values and the culture is the aggregate of everyone’s way of thinking and acting. Hiring for value fit assures you that you don’t have to micromanage or interview for every possible scenario they could encounter. You trust their judgment.
Hire for trust over performance Simon Sinek has a great video on how Seal Team 6 selects their members. They prioritize trust among team members over individual performance in building high-performing teams. This doesn’t mean not caring about performance, but that in order to construct the most high-performing teams, focusing on the trust among the members is more important than their individual performance. One way to identify high-trust leaders during interviews is to look for leaders who are honest, accountable, competent, humble, and empathetic.
Hire collaborators over soloists To build a high-performance team, you must hire individuals who find value in being part of a team. This is especially relevant for junior engineers who have not yet been part of a high-performance team and therefore see teamwork as secondary. These engineers are more focused on measuring their output in terms of lines of code, PRs merged, or tickets completed. During interviewing, probe around their most rewarding professional moments and what makes work enjoyable and listen for any mentions of collaboration.
Hire intrinsic over extrinsic motivators There are three parameters to calculate the horizontal range of a projectile (\(vo^2sin(2\Theta) \over g\)). Just like we approximated the volume of a chicken to be a sphere in Physics II, we can use projectile mechanics to estimate how far an engineer can go. If you want someone to go far is best to have high initial velocity, pointed the closest possible to the ideal direction, and minimize the deacceleration. In this contrived example, the deacceleration is the inevitable loss of motivation that we experience as humans as we go about any process. The responsibility of the leaders in your organization is to find people with the right initial velocity, point them in the right direction, and motivate them to minimize this drag. This becomes incredibly difficult if the person is motivated from external factors (money, praise, accolades) versus from within.
Hire “launched with (some) defects” over “launched when no defects” Conversely a projectile is not getting anywhere if it never launches. Often times engineers also tend to be perfectionists waiting for near-perfect conditions to deliver or release a product. Those who are comfortable with the process of learning, are comfortable with being uncomfortable.
Don’t forget, technical skills can be taught, and certain softer skills can be coached, but some traits are innate. Teach a man a technology and he’ll eventually become obsolete, teach a man how to teach themselves, and they’ll always be in need.
Process
Hiring is complex. You want to spend the least possible amount of resources to find the strongest signal that someone will be effective in their potential new role and organization. It should never be an attempt at clairvoyance, but a consistent and standarized methodology for the following key reasons:
- Eliminates bias
- Yields more consistent results
- Makes it measurable and therefore improvable
- Can be replicated as the organization grows
These are some fundamentals I’ve gathered over the years.
For hiring process:
- Dont create a process to find more yous. Create a process to find what you really need.
- What you need is not a title, is a set of outcomes.
- Half-assing it will considerably affect the results. Don’t force employees to participate in the hiring process if they don’t care to do it.
For crafting a role:
- Define it around outcomes.
- Be honest about the state of your organization and the desired outcomes and determine if this role is set up for success.
- If it would take someone in the top 1% of their field to achieve this, consider if you can compensate them accordingly.
For consideration during the interview process for each person:
- Can they individually be so productive that they raise the average team productivity output?
- Can they be a multiplier for everyone else?
- Is this person’s best work behind them or in front of them in their career?
- Does this person have 90% chance (high likelihood) of achieving the outcomes that only the top 10% of candidates could achieve?
- Who is on a team matters less than how the members interact. Does this person fit the team they would be a part of?
Here are my steps, crafted mostly from “Who: The A Method for Hiring” by Geoff Smart and Randy Street.
Role Proposal Document
Create a role/position proposal document with the following sections
- Goals
- Clearly define the expected outcomes with 3 to 5 SMART goals. Decompose each goal into:
- “We would be satisfied if you hit this target”
- “We would be impressed if you hit this target”
- “We would change our company logo to your face if you hit this target”
- What resistances will this role encounter?
- What are the key metrics they need to improve? Ideally, this is answered in the outcomes
- Identify the type: Will they be mostly building, leading, or correcting?
- If a builder, look for someone with a bias for action, who understands the iterative process of the MVP approach
- If a leader, look for someone capable of galvanizing (for example, did the interviewees feel energized during their chat?)
- If a fixer, look for someone who is even-keeled, assertive, and determined.
- Clearly define the expected outcomes with 3 to 5 SMART goals. Decompose each goal into:
- Progression
- What is the evolution of this role? Will you ever need more of this role, could it spawn off different divisions, or the formation of a reporting team?
- What are the potential career advancements for someone in this role, both laterally and vertically, and within what timeframe?
Competencies Don’t build an actual person, as it can lead to biases during interviewing. Only Identify key traits and skills.
- Profile
- Title
- Salary
- Level
- Who they report to
- Who reports to them
- Key partners
- Location/Remote
- Alternatives What are the alternatives to hiring for this role? What happens if it takes too long?
External Job Description
Craft the external job description leveraging the Job Proposal document:
Must include the basics: Profile, mission, responsibilities, “needs to have” (no “nices to have”, either they are needed or not).
Include the interview process, what they can expect and how long it’ll roughly take
Questions for the potential candidate to ask themselves, accompanied with the answer that would indicate a good match. This is particularly useful to filter out if constructed properly. Consider the following toy example: The position might be for a chef, but if the restaurant is on a luxury yacht, then the question is not “Do you like creating new dishes?” but rather “Do you enjoy being out at sea for hours?”
Internal Scorecard
Create the rubrik that will be filled out by the interviewers as the candidate goes through the process.
- Goals and outcomes
- Company values
- Competencies
Here’s the process visualized: 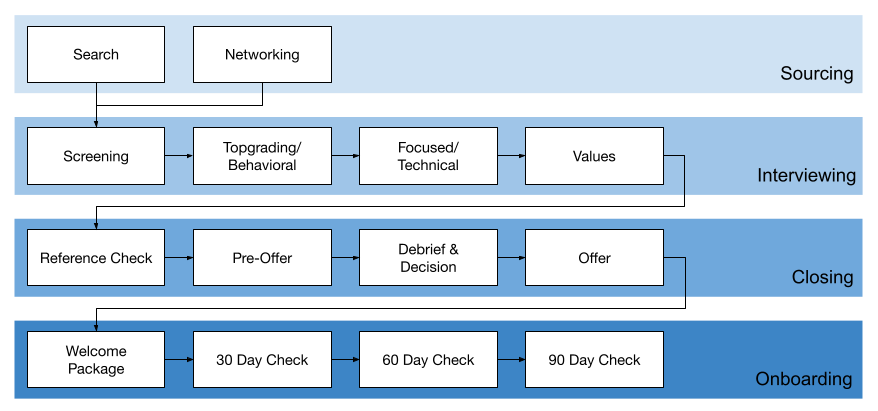
Sourcing
Networking:
- This should be done by anyone in the company at any time, whether in person or LinkedIn.
The best position to be in is when you open a position and you already have several warm leads to reach to who have expressed interest in joining when a position that fits them opens up.
Interviewing
Tony Lucadello, was a professional baseball scout for the Cubs and Phillies during the 40s and 50s and is considered by some to be one of the greatest sports scouts ever. He had an approach that was different from the other scouts at the time, watching players from different angles around the field. According to him, there were 4 types of scouts:
- Poor: Wastes time looking for games rather than having a planned itinerary
- Picker: Emphasizes a player’s one weakness to the neglect of all strengths and ignores the potential within.
- Performance: Bases his evaluation on what a player does in his presence.
- Projector: Envisions what a player will be able to do in two or three years.
He believed that 5% of scouts were “poor”, “pickers”, and “projectors”, with the remaining 85% “performance” scouts. When crafting your interviewing team, consider them against these archetypes for the role that is being considered. Obviously the “poor” scout is useless, but depending on the expectations of the role, the “picker”, “performance”, and “projector” all have their pros and cons.
Best Practices
Interviewing is a skill that requires practice and also an affinity and aptitude. They can be draining and stressful, but don’t forget that the other person is considering a major life decision and likely interviewing for a while. Provide the experience you would like to receive when being interviewed.
“People will forget what you said, people will forget what you did, but people will never forget how you made them feel.” - Maya Angelou
Before the interview
- Don’t read the notes of the previous interviewers as to not bias your own opinion.
- Use the restroom, drink water, bring the dog inside, mute Slack; prevent any possible interruption.
- Prepare your note taking document on your other monitor and write their name at the top
On the first 5 minutes of every interview
- Introduce yourself, who you are, what you do in the company
- Remind them of the length of the interview and what they can expect.
- Let them know that when they see you looking at another screen or typing, you are not answering Slack, but taking notes on your other monitor.
- Build some rapport and make the candidate feel comfortable.
Throughout the interview
- Take light notes, your focus should be on the candidate.
- Dig deeper with: “What”, “How”, and “Tell Me More”.
- Only interrupt if necessary to get the conversation back on track.
- Refrain from asking any illegal questions related to protected classes (age, race, gender, gender identity, religion, sexual orientation, marital or family status, pregnancy status, national origin, ancestry, physical or mental disabilities). Remember, they are interviewing you and your company as well.
At the last 15 minutes of the interview
- Remind them to ask questions and answer them.
- Thank them for their time.
Immediately after the interview
- Get some water, take a small break
- Finish writing down more detailed notes
- Based on your assessment and your assessment alone, write down one of the following “Strong Yes”, “Yes”, “No”, or “Strong No”. This will be used in the Debrief & Decision session.
Screening
Once someone applies, they promptly get scheduled for a call to get a quick alignment check on expectations, aspirations, and mutual fit.
Questions
- “What are you really good at professionally?”
- Check: Should match scorecard
- “What are you not good at or not interested in doing professionally?”
- Check: Should not match scorecard
- “What aspirations do you have for your next career move?”
- Check: Should be more about what they want to do, rather than what they want to receive
- “What makes a job engaging, fun, and motivating for you?”
- Check: Should match the environment of the role
- “What salary range do you expect from your next role?”
- Check: Should be within the budget
- “If hired, when is the earliest you could start?”
- Check: Should be within the required parameters
- “Let’s assume this goes well for the both of us and we do reference checks, how will your last couple bosses or colleagues rate your performance on a 1 to 10 scale when we talk to them?”
- Check: Reactions could quickly signal someone embellishing their resume
- “I would love to know about one thing you are passionate about/I would love to know about one of your most proud achievements, one that you can really brag about.”
- Check: The content is not necessarily that important, but how they convey the content. Extroverts and good storytellers could give a false positive and that is an acceptable risk. The objective is to unleash the candidate and have a conversation where you can get early signals for value fit.
Format
- One 30-minute phone call or Zoom/Google Meet session
- Conducted by either the hiring manager or someone from a Talent & Acquisition department (if there is one).
- Leave time at the end for questions from the candidate.
Topgrading / Behavioral
This interview should could follow the Topgrading methodology or the Behavioral-based technique.
If Topgrading
The interview asks the same questions (plus follow-up questions) throughout the last (or all) of the candidate’s career history. The main questions ask candidates about successes, mistakes, key decisions, key relationship, their manager’s strengths and weaker points, how their manager would rate them, and why they left the job. The theory behind this interview method is that the Threat of Reference Check (TORC) will cause many low-performers with exaggerated resumes to drop out, leaving a pool of theoretically honest and successful candidates. Candidates who are more willing to discuss the entirety of their career provide broader insights to interviewers.
Questions
- “What were you hired to do?”
- Check: If they can answer this
- “How did you define your priorities?”
- “What key metrics did you focus on?”
- “What were low points/What was your biggest mistake/Biggest lesson learned?”
- Check: Dig for growth and self reflection, no ego, no blame, growth and vulnerability
- “How were your team relationships?”
- Check: Lone wolf, team player, blame, collaborator
- “What accomplishments are you most proud of and how did you accomplish them?”
- Check: Are they outcomes or events/activities (fluff)
- “Why did you leave your job?”
If Behavioral
The interview focuses on a candidate’s past experiences, behaviors, knowledge, skills and abilities by asking the candidate to provide specific examples of when they have demonstrated certain behaviors or skills in the past as a means of predicting future behavior and performance.
Questions
- “How do you like to interact and communicate with your team?”
- Check: Do they mention daily standups, preference for collaborating, pair programming, pair up for ideation, triaging, etc
- “Tell me about a time you were most satisfied with your work?”
- “Tell me about a time you were most dissatisfied with your work?”
- “How do you manage burn out?”
- “What are key actions and steps you take to ensure quality?”
- “Have you ever proposed a new process/technology?”
- “How did you evangilize it?”
- “How did you get people to try it?”
Format
- One 60-minute Zoom/Google Meet session
- Conducted by hiring manager.
- Leave time at the end for questions from the candidate.
Focused / Technical
This is where you dig into the meat of their role. This interview will be very different depending on the role, department, seniority. However, the important consideration here is that it should resemble the actual work as much as possible, and not a Leetcode or HackerRank problem. If not, it can be very easy to pass on great talent:
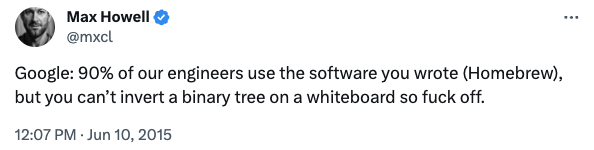 https://twitter.com/mxcl/status/608682016205344768
https://twitter.com/mxcl/status/608682016205344768
Interviewing.io publishes great insights about technical interviewing that are worth repeating:
Regarding interviews
- Interview should feel collaborative and not adversarial.
- The purpose of every interview is to “see if we can be smart together”.
Regarding a good technical interview question
- Layered Complexity: Where the initial question starts off simply and it builds from there. This also allows for quick benchmarking, as the lastly reached layer number is quick signals into the candidate’s technical ability.
- Real-world Relevance: Crafting the question or exercise in a way that retains the essence of the company work
- Algorithmic Leetcode or HackerRank questions are not preferred, but if still chosen, there should be some nuance and depth to make them fresh and interesting.
- Question quality (as assessed by interviewees) was found to be an extremely significant indicator for if a candidate wanted to move forward (whether the candidates did well or poorly).
Regarding general insights
- Interviewer being good at providing great hints (well-timed, didn’t give too much away) was found to be another extremely significant indicator for if a candidate wanted to move forward (also adjusted for candidate performance).
- Self perceived notion of good performance was very statistically significant as well for wanting to accept an offer as well as wanting to work with the interviewer.
- Resumes are a low-signal document.
- Technical interviews are a high-noise activity.
Other alternatives to coding exercises
- Pair programming sessions for a redacted feature or bug that is a stripped down version of something they would deal if hired.
- Live coding a reduced project that once again, is a toy version that maintains the essence of the real work.
- Portfolio discussion of a project that the candidate can speak to. This one does require a skilled interviewer to know which questions to ask to gain valuable insights.
- Take home projects can solve the uncomfortableness of coding while someone is looking over your shoulder. However, depending on the scope, they are often perceived as free labor or too much of a time commitment.
Potential Format:
- One 60-minute programming session
- One 30 to 60-minute system design session
- One 30-minute code review session
- Conducted by experienced engineers
One of the most debated topics for across engineering organizations is whether managers/leaders should maintain technical activities. Regardless of the expectation of coding, code reviewing, and architecting features and infrastructure, it is generally agreed that they should come from technical backgrounds and still retain that knowledge. Appendix A is a list of question to assess this ability.
Values
This is the last interview and it might seem like calling it an “interview” is a stretch. This is when the candidate has a chat with the CEO or top leader in their department to truly identify if the is a strong mutual value fit. The questions might change based on the values of the organization, but a list of common and important values alongside a couple of questions to get a signal on them from the candidate can be found in Appendix B.
Format
- One 30-minute phone call or Zoom/Google Meet session
- Conducted by executive or high-level leader in the organization
- Tell the candidate to ask questions as they chat, no need to wait until the end.
Closing
While everyone involved in the process should have been selling the company, the role, and the opportunity, the explicit action of closing becomes imperative the moment that it is decided you want to hire this person.
Losing out on a great candidate after going through the entire hiring process can be crushing. Once you get a sense that this person will likely reach the offer stage, you need to ramp up selling the opportunity to facilitate the moment of closing.
The urgency is imperative, as likely, you have the second-best candidate waiting without an offer while your first-choice is making their decision. Ending up losing both is devastating.
These are the key factors most people care about when making a decision. Throughout the conversations, identify which ones are the top priority for the candidate and make sure to sell them on those as they move through the stages:
- Company trajectory
- How much this role will add to their professional growth
- Culture and value fit
- Work/life balance
- Match with their team
- Location or remoteness
Reference Check
It is useful to consider the reference check as part of closing. Ideally, this step does not yield surprises but rather provides an opportunity to chat with individuals who can give you actionable information to not only set up the future new employee for success but also, to close them.
You should only contact “direct references”, and do not pursue “indirect references”. Understandably, the references provided by the candidate are most likely only going to speak highly of the person, but again, the objective of these calls shouldn’t be to disqualify the applicant. If that is the case, there is a major flaw in the interview process that needs to be corrected. What you want is to get third-party perspectives on what motivates this person, what makes this person shine, and what they struggle with, so you can develop a plan of action to make them grow and succeed in your company.
You should get 3 to 5 references, at least one of each for the following:
- Someone they reported to
- Someone they worked with
- Someone that reported to them (for managing roles)
Questions for someone they reported to
- “What were their most important achievements?”
- “What were their biggest learning moments?”
- “What was the most effective way to provide them feedback?”
- “Did you ever disagree? How did they handle it?”
Questions for someone they worked with
- “From your experience, what was this person really good at?”
- “Back when you worked together, what were their areas of improvement?”
- “Did you ever disagree? How did they handle it?”
Questions for someone that reported to them
- “Is there any professional growth that you can attribute to this person?”
- “What was their way of giving you feedback?”
- “Is there one main thing you learned from this person?”
- “Did you ever disagree? How did they handle it?”
Pre-Offer
It can be very useful to get a signal on the level of interest by the applicant before making a decision to make a decision on whether to extend an offer and the final details of said offer. One of the most effective methods is for the executive or leader performing the Values Interview to be ready to ask the following question in case they feel they would be a “Yes” at the Debrief & Decision session.
“In the case that we tendered an offer that made sense for you financially, do you see yourself joining our company?”
- If a “yes” with no hesitation:
- You are likely their first choice.
- If unsure:
- Ask what questions could you answer that could help clarify their decision-making process.
- Consider asking if they currently have any offers on the table that they are considering.
- If the candidate says they need an offer first:
- Reinforce the aspect of the question of “let’s consider that the offer made financial sense for you”. If still no concrete answer, ask if they have a timeline for when they are expecting to have a decision made.
Debrief & Decision
Ideally scheduled the earliest possible after completing the Reference Checks, as human recall is notoriously susceptible to distortion over time.
Procedure
- Everyone who participated in the interviews for that candidate must attend.
- Everyone must initially reveal their “Strong Yes”, “Yes”, “No”, “Strong No”. If there is one “Strong No”, the meeting can be shortened and most participants free to leave.
- Everyone gets around 2 to 5 minutes to present their assessment of the candidate.
- The hiring manager makes a decision.
Offer
You want to minimize or eliminate the possibility of negotiating. The unfortunate reality of this step is that at the beginning of this relationship, both parties have conflicting maxims of utility: The candidate wants to get the highest compensation possible, and the organization wants to spend the least possible. Moreover, the moment an offer is extended, your next-best candidate is in limbo. You should never extend more than one offer at a time, as rescinding it later will reflect incredibly poorly on the company and will likely result in a less-than-stellar reputation pretty quickly.
Procedure
- Prepare the offer details and schedule a call with the candidate.
- Be enthusiastic, tell them that the team is excited about the possibility of working with them.
- Proceed to say: “After concluding an analysis of market compensation for where you fit within your role, if we were to make the following offer <Explain the compensation details, cash, equity, benefits>, would you accept it?”
- If the answer is yes, then email them the offer right away.
- If the answer is “I need the offer in writing”, they likely want to negotiate or shop around with your offer.
- Explain the truth, how the organization considers the people they hire to be their biggest asset, and therefore the company makes sure to offer the best package possible. Not doing so means that negotiating is an option, which is another way of saying “We believe you are worth X, but we want to try to get you for X - Y”.
- You can also explain how the moment you extend an offer, no other offers are going out the door, which opens up the possibility of losing the next-best candidate.
- If the answer is “no” to either scenario or repeated attempts to negotiate, thank the candidate and tell them that you understand if they consider the offer to not match the value they could provide and that you wish them the best in their search.
Onboarding
The moment the candidate accepts their offer is when onboarding begins. This person just made a big life decision and first impressions are lasting. Make sure they don’t feel forgotten or confused about next steps.
Keep the excitement going
- Have a prepared email with details on next steps.
- Have them chat with people in their team.
- Have a swag package ready to be delivered overnight.
- Send them a video recording of all the excited reactions during the last meeting when the hiring manager told the team that the candidate accepted.
Onboarding is critical. If not done right, there are 3 likely outcomes
- The person will quit.
- The person will be ineffective.
- The person will be resentful.
Be prepared with a template for a 30/60/90 day plan:
- With specific, measurable goals.
- Relevant to the role.
- Should be collaborative, with review and buy-in from new hire.
- Achievable, with early wins to build confidence.
- A good rule of thumb is for the first week to revolve around gathering context, get set up, start relationships, and ask questions; and for the second week to get a tangible, concrete (albeit small) win.
Review 30-60-90 Day Plan.docx for an example template.
Measuring
Unfortunately, while hiring is one of the (if not the) most influential and critical action for your organization, little is done to measure, learn, and improve it. Understandably, the way you refine or improve any process, is by measuring successes and failures. In this case, we have an asymmetrical access to the data, we know the performance of the people hired but we don’t know the performance of the people passed on.
What can be improved or what does it mean to improve hiring? It means to improve the hiring process such that it:
- Doesn’t pass on strong candidates, only on poor candidates.
- Hardest one to measure as it requires checking where the candidate ended up after about a year from their application.
- Takes the least amount of time and resources as possible to yield the results.
- Expensive to measure as it requires experimenting with the process.
- An alternative is to review the scorecards for each hire at their one year performance review. Look for any statistically significant interviews or interviewers that most consistently match the performance review.
- Yields more people being incredibly successful than unsuccessful.
- Same as the previous one.
- Results in high candidate satisfaction, regardless of outcome
- Send them an anonymous survey with a $20 gift card upon completion that doesn’t share the results until at least 10 candidates have responded with the following questions:
- How good were the questions? (1 to 5)
- How helpful was your interviewer in guiding you to solutions? (1 to 5)
- How excited were you to work with the company? (1 to 5)
- How was the length of the process (too short, about right, too lengthy)
- Free form comments
- Send them an anonymous survey with a $20 gift card upon completion that doesn’t share the results until at least 10 candidates have responded with the following questions:
Effective People Leadership
This will be tackled in three ways:
- Leading engineers
- Leading leaders
Leaders must deliver business goals through the leverage of :
- Performance
- Producitivity
- Happiness
However, this is only half of the equation. For these people to function and deliver, they need to work as a team. And if you want them to be a high-performance team, there are several components that must be handled:
- Identity Definition
- Goal Setting
- Collaboration & Dynamics
- Conflict Management
- Decision Making
Lastly, there are unique and new challenges in leading and team building in a remote world. The last section summarizes several tips.
Leadership Principles
Depending on the scope of leadership (e.g.: of a team, of a department, of an entire organization), the implimentation of these principles shifts with the focus. According to Ford, there are three effective leadership focuses:
- Tactical leaders focus on solving straightforward problems with operations-oriented expertise.
- Strategic leaders focus on the future, with an ability to maintain a specific vision while forecasting industry and market trends.
- Transformational leaders focus less on making decisions or establishing strategic plans, and more on facilitating organizational collaboration that can help drive a vision forward.
When leading at scale, your output transitions from tactical and specific, to strategic and holistic. Broad over deep, abstract over details. As you traverse down this list your technical expertise is less relevant than your ability to influence motivate, detect patterns, competently assess trade-offs, align interests and goals, organize people, build effective processes, policies, and structures.
This is by no means an all-encompassing list of all activities and behaviors of a great engineering leader, but they have worked for me:
Act on High Leverage: Prioritize activities that only you can perform and that have the most significant impact, rather than merely focusing on what you’re good at.
Align: Ensure that the goals of every team align with each other. Even if each team individually meets its goals, misalignment can lead to inefficiency or decline.
Be Vulnerable: Embrace mistakes as part of the growth journey and don’t fear them. Worry more about failing your team and customers than making mistakes.
Coach and Mentor: Provide guidance and mentorship to nurture your team’s growth and development.
De-risk Everything: Your teams work to find the best solutions, and your role is to identify the balance between achieving the best outcome and managing risks effectively.
Delegate: Divide complex tasks and delegate responsibilities effectively. Only engage in tasks that require your unique expertise.
Detect: While your teams focus on specific issues, it’s your responsibility to see the bigger picture and identify any blind spots or processes that are stuck in the status quo.
Develop Contextual Intelligence: Develop an understanding of different cultures to work effectively in diverse environments.
Diversity of Thought: Create an inclusive environment that values diversity and different perspectives.
Empower: Focus on scaling your efforts to empower and unleash the potential of others.
High-Standards Culture: Lead by example and foster an environment of excellence and compassion. Ambitious goals require astounding support.
Knowledge not Hierarchy: Priority and importance is not based on seniority or title. Allow those with valuable knowledge and experience to have a prominent voice.
Make Yourself Obsolete: Your aim is not to render yourself unnecessary due to incompetence but to build self-reliant teams.
Manage Conflict: Understand human behavior to navigate constructive disagreements effectively.
Negotiate: Master the art reaching mutually beneficial outcomes. No “zero-sum” games.
Never the Expert: Foster a mindset that views challenges as opportunities for growth.
The Right Focus: Build your team’s identity around solving problems, not just delivering solutions.
Prioritize: Distinguish between urgent but unimportant and important but not urgent tasks.
Satisfice Decisions: Focus on choosing the most practical solution, rather than aiming for the ideal one. Make high-level strategic decisions and empower your teams to decide on the detailed implementation.
Leading Engineers
There is a vast body of research, literature, and teachings on the subject of leadership. Particularly, of individuals with specialized skills and knowledge that, ideally, exceeds yours. Combined with the never-ending need to coalesce multiple groups of talents to pursue a common goal, it can become an exercise in futility to only lead what you are an expert on.
Leading is not:
- A reward for knowing how to do something better than others
- Telling someone what to do
- Micromanaging their every move
- Abandoning individuals when they encounter challenges and favoring only top performers.
Leading is:
- Understanding who a person is
- Grasping what motivates them
- Nurturing their personal and professional growth
More importantly, why is it needed at all? Engineers are clearly smart, can’t they lead themselves? I find a useful analogy in a vehicle’s manual gearbox.
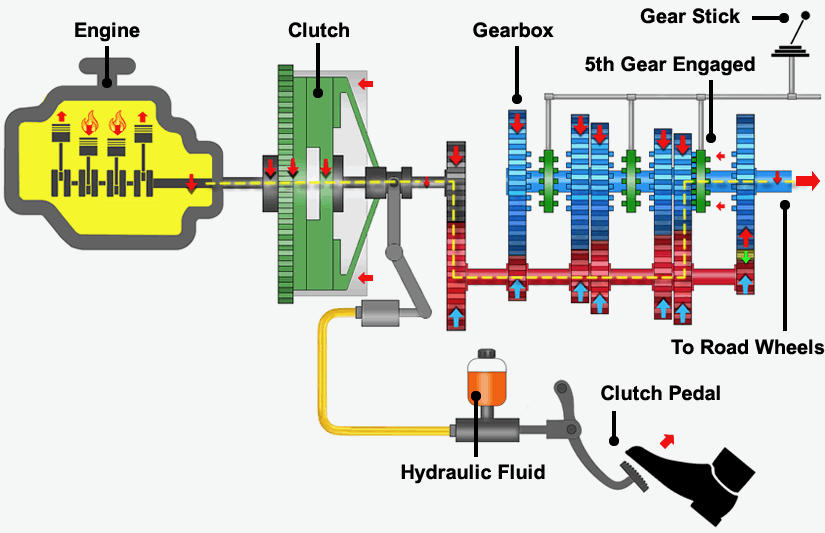 https://learndriving.tips/learning-to-drive/how-to-change-gear-in-manual-car/how-manual-car-gears-work/
https://learndriving.tips/learning-to-drive/how-to-change-gear-in-manual-car/how-manual-car-gears-work/
A transmission has multiple gears, each facilitating the optimal distribution of power to the wheels through a clever combination of gear ratios. The presence of a clutch allows for the imperfect action of shifting gears while the engine spins at thousands of revolutions per minute. However, for each gear at rotating at a specific wheel speed, there’s a corresponding engine velocity (RPM) at which you can shift without a clutch. This is very challenging and risky, and a slight misstep can result in gear grinding and damage to the transmission. The clutch bridges the gap, allowing the engine and transmission to operate independently, yet harmoniously. A (good) leader performs the same function. They do not meddle with the engine or the transmission; instead, they enable each component to perform at its best.
I try to avoid the word “manager”. It is a remnant from the industrial revolution where work was mechanical but done by humans. Factories filled with replaceable low-skilled or unskilled laborers who just needed to keep the floor operating. You manage the unexpected, you manage scenarios and circumstances, you manage projects, and you lead people, you lead towards goals and ideal outcomes.
Motivation
This section is informed by Dan Pink’s book “Drive: The Surprising Truth About What Motivates Us”. It’s essential to understand the two primary sources of motivation:
Intrinsic (from within)
- Autonomy
- Mastery
- Purpose
Extrinsic (from outside)
- Money
- Praise
- Accolates
Historically, contingent motivators were highly effective when work primarily involved simple, mechanical tasks that demanded more focus than creativity. These contingent motivators rewarded task completion and its speed. For example, “Build 10 chairs in a day and earn \$100, build 20 chairs in a day, earn \$250.” Entire management processes and policies built around these incentive structures were prevalent during the industrial revolution when work mostly required staying focused, adhering to straightforward rules, and pursuing known solutions.
However, when tasks involve cognitive functions beyond the rudimentary, motivation through extrinsic rewards ends up being counterproductive. Work that necessitates creativity, problem-solving, and inventiveness responds more favorably to intrinsic motivators.
- Autonomy is the desire for independence and the ability to have control of our lives.
- Mastery is the desire to become proficient and excel at something that matters to us.
- Purpose is the desire to connect our talents and contributions to a greater cause.
In practice, you should consider the nature of the motivation you seek to instill:
- If you require compliance, managing and deploying extrinsic motivators might be appropriate.
- If you aim for genuine engagement and a high level of commitment, the path to success involves leading and creating an environment that fosters intrinsic motivators.
Performance
One of the most critical activities as a leader of a team, is to address early signs of low performance.
If someone is failing at something they were good at, there is a human issue that needs to be addressed.
If someone is failing at something they’ve never done before, there was a leadership failure for putting the person there before they had the tools, knowledge, and skills.
There are many causes for low performance, but the most effective tactic to correct it is to treat it like physical therapy:
- Build up confidence with small feedback loops of wins
- Build a plan together with specific time frames, goals, and agreements
Feedback
One of the most pivotal skills for any leader is the art of providing feedback. Effective feedback requires a delicate balance of several key elements:
High degree of empathy: Understand the emotions and perspectives of the person receiving feedback. Empathy is the bridge to fostering a supportive feedback environment.
Candor and respect: Candid feedback is crucial, but it must be delivered respectfully. Be honest without being harsh or judgmental.
Genuine care in the growth of the person: Convey a sincere commitment to the individual’s growth and development. Your feedback is not about pointing out flaws but helping them improve.
Feedback should meet specific criteria:
Be Specific: Address particular behaviors or actions rather than making general or vague statements.
Delivered Timely: Give feedback as close to the observed behavior as possible. This ensures that the context is fresh and vivid.
Focused on Actions, Not Assumptions: Base your feedback on observable actions, avoiding assumptions or inferences.
Open to Correction: Be humble and willing to be corrected if new information comes to light when you provide feedback.
To structure your feedback most effectively, consider this expansion from the SBI model (Situation, Behavior, Impact, Correction, Support, Commitment):
“In our last team meeting (Situation), when discussing the project timeline, you interrupted multiple team members and spoke over them (Behavior). This prevented us from effectively sharing our ideas and caused frustration among the team (Impact). I need you to improve your communication and collaboration skills (Correction), which I know you can do (Support), and I am committed in helping you do that (Commitment).”
It’s vital to acknowledge that receiving feedback can trigger an amygdala response, a sensation of “fight or flight” with fear or anger. When this happens, higher cognitive functions are reduced causing the person to not be open to constructive comments. Seek buy-in before engaging: “Is now a good time for us to talk for a few minutes? I’d like to share some feedback.” If properly hiring for value fit, people with growing mindset and humility will receive this positively.
Remember that effective feedback should be a regular and private practice. Public positive feedback can be a powerful motivator, but be mindful of individual preferences as some team members might prefer a more private acknowledgment.
Plenty has been studied and published on the subject of feedback. The following are some useful summaries:
A well known “Critical Positivity Ratio” (also known as the Losada Ratio), which stated that there was a 5.8 to 1 positive-to-criticism ratio for high performing teams and 3 to 1 for professional athletes, has been retracted and its claims deemed unfounded.
“Radical Candor” by Kim Scott provides a straightforward framework built on a strong personal relationship, allowing for extreme candor when giving feedback.
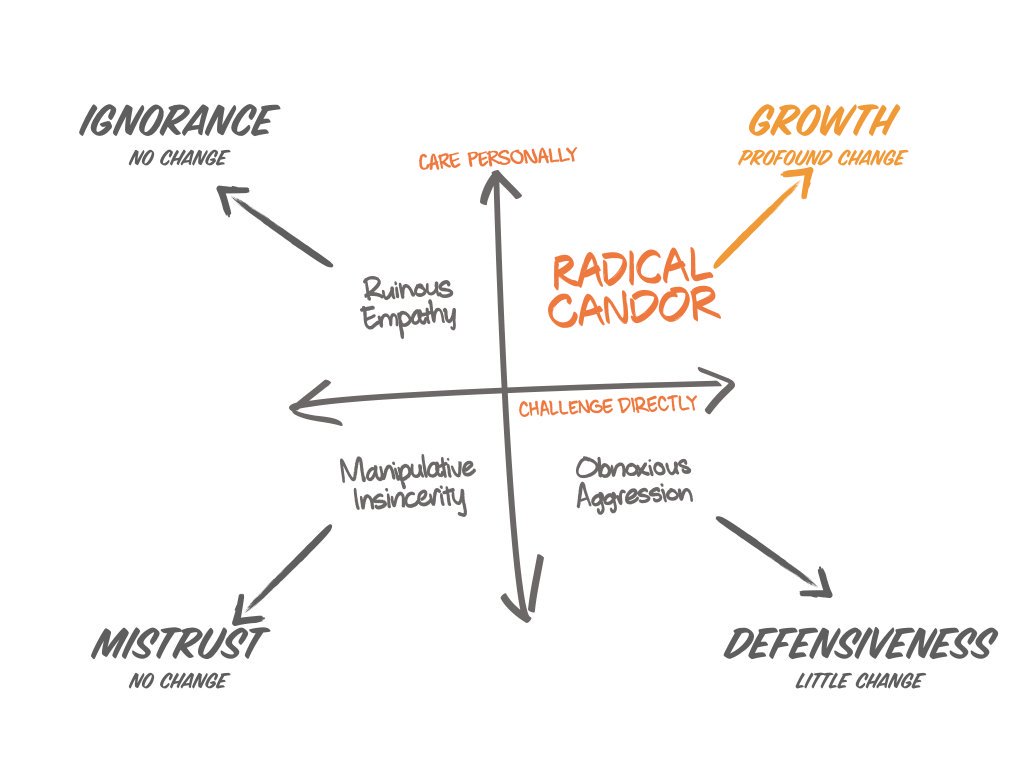 https://jamesosborn.co.uk/2018/07/30/radical-candor/
https://jamesosborn.co.uk/2018/07/30/radical-candor/“Thanks for the Feedback” by Stone and Heen, points out the importance of learning how to receive feedback before learning to provide it.
“Dare to Lead” by Brene Brown presents the steps to build the courage and go from “armored” leadership to “brave leadership”. The book presents great arguments on the value of vulnerability and trust.
One-on-Ones
One-on-one meetings, often referred to as 1:1s, are among the most valuable tools in a leader’s toolkit. In fact, they are likely the most important time in your calendar. These recurring meetings between you and your team members hold immense potential for:
- Building strong relationships
- Facilitating constructive feedback, both giving and receiving
- Supporting career growth and aligning with objectives (OKR check-ins)
- Sharing essential information
- Aligning priorities
It’s crucial to understand that one-on-one meetings are not the time for status checks. If you find yourself asking for project updates, you need to improve your syncs or stand-up meetings. One-on-ones are dedicated to individuals and their career growth. It’s not about the company and its goals, it’s about the individual and theirs.
Procedure
To make the most of your one-on-one meetings:
- Ideally, schedule all your one-on-ones on the same day to minimize context switching between different types of work.
- Maintain an ongoing, private document to track discussion items. This allows both you and your report to share mutual accountability and have a record to rely on (Axiom 1).
- Follow a consistent format. Use the shared document for updates between sessions.
Meeting Format
Top of Mind or Highlight of the Week: Begin with immediate needs, issues, or exciting developments.
Blockers: Review any “blockers” outlined in the document.
Action Items from Last Meeting: Build a culture of accountability by revisiting the “action items” from the previous meeting. What commitments were made, and were they fulfilled?
Bidirectional Feedback: Create a culture of growth through feedback. Prepare your feedback in advance, categorizing it into medium, high, and critical. Transfer any medium importance items to the “high” category, and discard any non-essential items from “medium.” Your “critical” category should remain empty, as any critical issues should have been addressed before the one-on-one.
Priority Alignment: Discuss any changes in priorities or alignment issues since the last session. Was any deviation justified?
Ask, “How can I help you this week?”: Your role is to enable your team members’ success. Ask them how you can assist them in their current endeavors.
Ask, “What experience didn’t match your expectations this week?”: Encourage open communication about challenges and expectations.
Freeform: The final part is where relationship building occurs naturally. Engage in a casual, freeform conversation.
Action Items: Document any identified and defined tasks during the meeting.
Document Format
- Blockers should be outlined by the report, ideally with proposed solutions, or at least, what has been attempted.
- Priorities are a collaborative effort, with your report’s input and adjustments during the conversation.
- Action items should be documented together to ensure clear follow-up.
As a leader, it is imperative that you keep in mind that the work they are doing, this project, and their time at your organization is transient. The mutual agreement is that you receive the benefits of their talents in exchange for financial compensation and helping them reach their professional goals. Your job is to uncover where they want to head and guide them on the journey. Your success isn’t about squeezing every drop from them now; it’s about how they’ll reminisce about this phase in their career a decade from today. Was it a game-changer, a time of tremendous growth? Strive for a wholehearted “yes.”
Now, here’s a word of caution: don’t push growth for growth’s sake. Some folks aim to meet the essentials, and that’s it. You have to decide if this matches the values and objectives of your organization, but trying to change that behavior in a person is a recipe for frustration and resentment on both sides.
And remember, growth doesn’t always mean climbing the promotion ladder. Everyone’s journey is unique. As a leader, your role is to guide, not dictate their path, helping them uncover their goals and chart their course.
Anti-Patterns
Leading people means being able to recognize behavioral patterns, to pick up what is not being said explicitly, to have the compassion and patience to “hug the cactus” with them and help them let go of it. An entire branch of science is dedicated to this, so it would be futile to try summarize it all. However, there are some anti-patterns to behavior to watch out for.
- The Persecutor: Blame is their core emotion, and they attack to feel superior. It’s always everyone else’s fault and never theirs. If they ever do accept it, they become an “Angry Victim”. They take no responsibility, critize and belittle others. However, they don’t take action, they just like an excuse to attack others.
- The Victim: Fear is their core emotion, and they self-flagellate emotionally and intellectually to feel inferior. They are constantly opressed, helpless, and ashamed. They make no decisions, avoid responsibilities, and waste time of those around them having to repeatedly cheer them up.
- The Rescuer: Pride is their core emotion, and they rescue to feel superior. They use the “I’m just getting things done” as a cover for directly or indirectly minimizing others’ skills. They meddle everwhere unnecessarily and don’t allow others to grow.
- Punisher: “Hit the sales target or you won’t get that promotion”
- Self-Punisher: “I’ve worked overtime every day this week; I’m sacrificing my personal life for this project”
- Sufferer: “I’m already so overwhelmed, and now I have to do this other task as well”
- Tantalizer: “If you meet this deadline, I might get you that promotion”
- Acronym for “Deny, Attack, and Reverse Victim and Offender” is a reaction manipulation strategy when perpetrators are confronted for their behavior: “What? I didn’t delete that environmental variables on the prodution environment. You are not my boss so back off. Actually, it was probably you and now you are trying to blame it on me”
Leading Leaders
Your maximum effectiveness is in finding and coaching leaders who unlock the best of their respective teams.
Pay attention for the following anti-patterns and actively seek to coach against them:
- Not delegating: The most common, especially among new leaders. They fail to delegate work and take it on themselves. Some likely causes:
- Unsure about leader skills, so focusing on what they know they do well
- Their team is understaffed or improperly staffed
- Team is properly staffed but there is a lack of trust
- Believe they are leading by example
- Believe they can do it all
Not following “servant leadership”: They believe leading is telling people what to do, and not an act of service through coaching, teaching, and motivating.
Not building trust with and within the team: Failing to recognize the main leverage as a leader and the primary dynamic of a team.
Not adjusting the relationship: Trying to be the “friend” of the team.
Not adjusting their mindset: Failing to understand their goal is not to be Michael Jordan but Phil Jackson. They role is to be a catalyst and remove road blocks, not getting the ball in the net.
- Not acting fast enough: They wait too long to take action or even to communicate issues. Some likely causes:
- Unsure about how they are perceived as leaders, so trying to fix before anyone finds out.
- Believe they need to have all the answers now that they are leaders of a team.
- Not giving good feedback and/or failure to follow the main tenants of providing feedback: Routinely, in a timely manner, effectively by not being too subtle or too abrasive, not focusing on actions. Some likely causes:
- Being afraid of confrontation and “being disliked” by their team.
- Believe in “one-size-fits-all” approach that fails to embrace empathy and individuality when approaching each team member.
- In a similar vein, providing feedback only the way they would like to receive it.
- Not realizing the impacts of their words, actions, and attitudes: Failure to understand the influence they have on the morale and mental well-being of the team as their leader.
Not being transparent enough: A confused team that feels they are being kept in the dark with certain information will have diminished performance.
Not being protective enough: Conversely, overburdening the team with all the “behind the scenes” knowledge can also cause diminished performance.
Not setting clear goals: The team is performing and delivering, just not towards the right objectives.
Not hiring properly: Not abiding by the guiding principles and making common hiring mistakes, like hiring similar to them, compromising the bar, or avoiding it altogether.
Not giving the team credit: They use mostly “I”s when describing their output.
Not building cross-functional relationships: Failing to understand that one of the most effective ways to unblock your team is if you have social capital among peers.
- Not asking for feedback
- Not adapting to the strengths and weaknesses of the team
- Not having courage to say what everyone knows but isn’t saying
- Not having good “meeting” hygiene
- Not having self-compassion
It might be tough for a lot of leaders to reach out for help. They might recognize their anti-patterns but be unsure how to break out. Create informal groups of 3 to 5 leaders in nearby timezones but not in the same division. You want them to share “what has been challenging this week” in confidentiality, no one they report to and ideally not a peer with whom they work with closely, which could prevent them being vulnerable. Vulnerability is the key in this group and any retaliation or usage of privileged information in these sessions will not be tolerated.
According to the Situational Leadership Model the most succesful leaders are the ones that adapt their style to the performance of the individual and/or group they are attempting to lead or influence.
 Image by Penn State University
Image by Penn State University
Measuring
Gallup has done research across 100,000 teams and found these 16 questions to be the most effective at gauging employee engagement
DePaul University has a rubrik for leaders to do root-cause analysis into a particular performance issue with an employee
This test evaluates and maps the information processing preferences of the members of a team: https://johnmattone.com/about/assessments/iopt/
Effective Team Leadership
“There exists a whole that is a greater than the sum of its parts” - Aristotle
You can have a team compromised of individuals of the highest caliber in their field, but if there are issues related to teamwork, coaching, and an overall poor team dynamics, the results will be disastrous.
A great example is the 2004 U.S. Men’s Basketball team at the Athens Olympics, dubbed “The Nightmare Team”. Even if you don’t know much about basketball and the NBA, you’ve probably heard of LeBron James, Dwyane Wade, Allen Iverson, Tim Duncan. If you know a bit about the sport, you’ve probably heard of coach Larry Brown, an inductee of the Basketball Hall of Fame, and the only coach in basketball history to win both an NCAA championship and an NBA title. You’d think this team was set to sweep the Olympics. Sadly, they lost the first game by 19 points, the largest margin of defeat for the U.S. in the Olympics, and lost three total games, the most ever by the U.S. men’s Olympic basketball team.
This outcome can be attributed to multiple shortcomings:
- Clash between the coaching style and player expectations.
- Player egos, as each was a primary figure on their respective NBA teams.
- Non-existent team chemistry due to a lack of practice and bonding time.
- Poor team dynamics driven by lingering NBA rivalries, hampering communication and teamwork.
These factors are not unique to basketball or sports. While on paper the team could’ve been close to ideal due to the individual performances, those are not the most important factors to analyze to gauge team effectiveness. Rather, examine them with the following questions:
- Do team members value being in a team?
- Do they perceive others merely as steps to individual prominence?
- Does the leader demonstrate a genuine interest in understanding each team member’s strengths and challenges?
- Is trust nurtured within the team?
The primary contract and leap of faith between a leader and their team is this:
- The leader offers psychological safety.
- The team reciprocates with vulnerability.
Constructing a highly collaborative team within an environment of psychological safety, fostering trust and vulnerability, where all understand that failure is an option and that decision-making can proceed even when disagreements arise, results in a team that:
- Is not just producing short-term gains, out of fear of taking risks.
- Attempts the impossible and fails, yet lands further ahead than it was thought possible.
- Experiences contentment, growth, and continuous learning, enabling the leader to take risks elsewhere and scale their effectiveness.
Google’s Project Aristotle Who is in the team matters less than how the members interact, how they structure their work, and how they view their contributions. Every quarter have an anonymous survey across your entire organization:
- Can we take risks together without feeling mocked or embarrassed?
- Can we count on each other?
- Are goals, roles, and execution plans clear?
- Are we working on something we care about?
- Do we believe our work matters?
Trust
This section borrows from research by Jeb Hurley’s “Re-Thinking Team Leadership in a Hybrid / Remote World”, and Simon Sinke’s findings, particularly from “Leaders Eat Last: Why Some Teams Pull Together and Others Don’t”. Trust is the cornerstone of any high-performing team and any team striving to become or stay at that level must prioritize not only individual performance, but team trust. Reason why it is the basis for Hiring Principle #2.
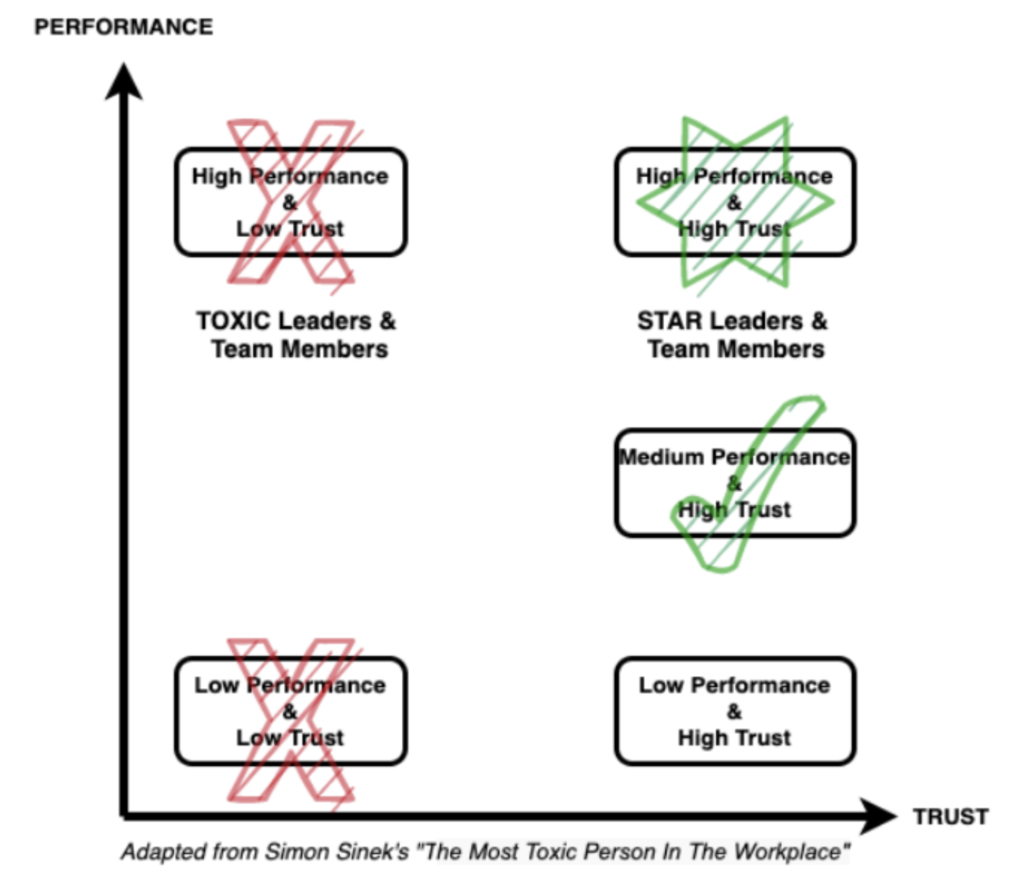 https://kodopeople.com/blog/
https://kodopeople.com/blog/
Trust shouldn’t be an abstract concept. It should be measured and fostered. Now more than ever building trust becomes harder in a remote environment. GitLab, the largest 100% remote tech shop, shares that the three components that build team trust are:
- Trustworthy Behavior: When members act with candor, respect, transparency.
- Biochemical Responses: When members experience the release of oxytocin, dompanic, norepinephrine in their bodies.
- Trusting Dynamics: When members repeatedly receive and participate in the cycle of experiences matching expectations. Moreover, when the cycle goes in the other direction, of experiences not matching expectations, this releases cortisol (the stress hormone), which inhibits the release of oxytocin.
It then becomes clear that great leaders must act on this knowledge and not only grow the individual performance of their team members but coach the team relationships.
The effective engineering leaders:
- Understand human behavior and have high empathy.
- Inspire individual intrinsic motivators: Autonomy, Mastery, Purpose.
- Actively create interactions that result in positive team dynamics.
- Themselves embody trusting values, personal and organizational, and align them with the team’s purpose
- Relentlessly monitor behavioral changes and gaps in trust dynamics, taking immediate action when necessary.
While great leaders coach and instill these traits, it becomes clear why hiring is so critical. If you hire someone that does not have matching values, is not intrinsically motivated, and is naturally distrusting, that one individual will prevent the cohesion of team. In turn, this will cause you, as a leader, to have to spend more time on this team to compensate for the broken dynamics. Now, you are unable to spend more time to serve other teams and lead into new endeavours. This one improper hire affected all the way up the chain. Ineffectiveness sifts upward.
While the leaders create the environment, the participants need to maintain it. Everyone added to the team needs to commit to contributing in keeping it so:
- No feigning surprise: Avoid reactions like: “You don’t know that data structure?”
- No well-actuallys: Avoid pedantic corrections that have no effect in the decision or conversation only to say “I know this and you don’t”
- No back-seat driving: Don’t interject yourself in someone’s work, unless asked to participate
- No subtle -isms: No subtle acts of racism, sexism, homophobia, transphobia, or any discriminatory comment against a protected class. Some can happen by mistake, when that happens, apologize.
Code of Conduct:
- Don’t ridicule other’s mistakes
- Don’t ridicule other’s questions
- Don’t ridicule other’s work
- Explanations are given intent to help and teach, not embarrass and show-off
- Responses are kind, helpful, and patient, not condesending, snarky, and in poor tone
- Disagreements are about finding the best solution, not about winners and losers
- Seniority or organizational hierarchy have no bearing on respect
Decision Making
A core trait of a highly efficient team, is the ability to make healthy decisions. Opinions are shared freely, respectfully, and without arrogance. Similarly, listening is always done with intent and openness.
Making decisions is not about winning or any one single proposal edging out the others. It’s about collectively agreeing on the best course of action based on the information available. This clarification is important, since down the road and with the benefit of hindsight, the decision not taken could end up being more beneficial. It is valuable to examine these situations to learn how to make better decisions in the future, but always consider the information you had at the moment the decision was made.
Types of decisions:
Cheap Reversible Decisions: These have the lowest of stakes, if you go down one path, it is easy to change course if needed.
Expensive Reversible Decisions: Still able to change course but it incurs in some complexity and costs.
Irreversible Decisions: These are the choices that have consequences, costs, or resource requirements that effectively, make them irreversible.
Types of agreements:
- Consensus: When all team members are in agreement.
- Democratic: When most team members agree.
- Autocratic: When one person makes the decision.
If agreement is not through consensus, everyone should still be able to see how the chosen decision was derived, even if they disagree with the metric. Any disagreement should be on the implementation, not on the maximum utility. Otherwise, the parties are not deciding about the same thing.
Considerations:
- Time (what is the timescale of this decision?)
- Costs
- Unforseen impacts (review Aligning Goals and Incentives)
Execution Commitment: Once the team has given due consideration to the decision, the most effective teams commit and execute, as well as record and revisit. Avoid wasting too much time and mental energy on second-guessing. If the team is uncertain about the solution chosen, take these steps:
- Agree on when and where checkpoints will be.
- Define the measurements that will be made.
- Specify a range of results and the actions that will be taken for each.
All the inputs and considerations are usually forgotten by the next big decision. By recording everything once all the noise has been cleared, you are able to quickly audit the process if data has changed to know if to take a different path in the future, or if to correct the one you are on.
Conflict Resolution
Disagreeing is a healthy and necessary interaction of any effective team. Constant unanimity means the team might as well be one person because it is not getting the benefit of multiple unique and diverse minds. When engaging in a healthy debate, consider the 4 tenants of Nonviolent Communication by Marshall Rosenberg:
- Observation: Describe what you see and hear and avoid any judgement.
- Feelings: Identify and express your feelings towards the observations
- Needs: Recognize what human need is behind what you are feeling.
- Requests: Clearly, respectfully, and with specificity communicate which request will meet your need.
Very often, unhealthy interactions are resolved just with steps 1 and 2. Human language is a very imperfect data transfer mechanism. It is highly contextual and not explicit, which means the symbols and syntax we use to convey information might have slightly different meanings between a sender and a receiver.
To add another layer of complexity, not only is the communication system lossy, but commonly, the underlying utility two disagreeing parties are trying to maximize are different. This is not often obvious. Two people arguing because they are not realizing that while they are debating the same topic, their underlying utility they are trying to maximize is different, and therefore they can’t reach an agreement.
“Maximizing Utility” is a core idea in Utility Theory. It’s about making choices that maximize your overall satisfaction or well-being. In essence, it means making decisions that give you the greatest benefit or happiness based on your preferences and constraints. This yields a few scenarios:
Incompatible Preferences: Situations where the preferences or utility functions of two or more parties are fundamentally at odds, making it difficult to find a mutually agreeable solution.
Pareto Efficiency: In economics and game theory, Pareto efficiency is a state where it’s impossible to make any individual better off without making someone else worse off. In a conflict with differing utility functions, achieving Pareto efficiency can be challenging, as the parties often have conflicting interests.
Zero-Sum Game: This is a concept that describes a situation where one party’s gain (or utility increase) is exactly balanced by another party’s loss (or utility decrease). In such scenarios, it can be particularly challenging to find a win-win solution, as any gain by one party comes at the expense of the other.
Once messages are clarified and utilities agreed on, always debate the strongest point of the other party, not the weakest. Don’t think “one of us will be the loser of this disagreement”, instead never forget “we are both trying to agree on what the best approach to this situation is”.
Lastly, a few key considerations to keep in mind:
- People are not their ideas
- Changing your opinion, is not losing
- “Strong opinions loosely held”
- Have grace and allow people to clarify their intent
Collaboration
“If you want to go fast, go alone. If you want to go far, go together” - African proverb.
Coding is a solo endevour, software development is a team effort. While many go into computer sciences because they believe they won’t have to deal with many people, in reality it is quite the opposite. Even Markus “Notch” Persson says that he didn’t develop Minecraft alone, he collaborated with early fans who found bugs and contributed key features.
I’ve found that those that prefer the individual route is because they haven’t been part of a high-functioning team. The benefits are invaluable:
Verification: A highly collaborative team is continuously checking correctness, yielding earlier issue detection, removing unnecessary redundancies, and self re-aligning towards the right goal.
Growth: Knowledge is constantly distributed and shared. When one member learns something, they share that knowledge with their team. Moreover, high-collaboration usually results in members knowing the learning styles of their colleagues, making the knowledge sharing even more efficient.
Speed: Initially, it is undeniable that you can “get more done” by yourself. However, the initial investment of building a collaborative team quickly pays off and eventually results in reaching goals faster.
A succinct statement to remember: “Relationships outlast projects”
This is a broad topic, however here are some concepts and tips to consider:
Production blocking: No matter how large the group, individuals can only express a single idea at one time if they want other group members to hear them. Studies have found that the number of suggestions plateaus with more than six or seven group members, and that the number of ideas per person declines as group size increases.
Work style: Each individual has their preferred strategy when tackling challenges. In software, some like to jump straight in, move fast, break things and see how they behave. Iteration is their game. For others, they prefer to research and understand as much as possible before attempting anything. These individualities can get in the way of healthy collaboration if not aware.
Personal READMEs: Create and maintain a document that answers some basic questions and helps others collaborate with you. Consider a Johari Window or the questions in Appendix « TODO! »
Vulnerability
This is one of the key values that must be shared by every individual of an effective team. Unfortunately, vulnerability it is often perceived as a sign of weakness. This couldn’t be further from the truth. Vulnerability means to have confidence, to have the ability to understand our thoughts and emotions and the ability to express them with respect and clarity.
Moreover, it means not wasting time. It means being able to admit when you are wrong, and to allow your opinions to be changed when new information is presented to you. A lot of time and productivity is wasted holding on to ego.
Saying sorry is a strength, not a weakness. The people learning the most, will make the most mistakes. The people attempting the most, will have the most failures. In fact, we should all strive to have statistical power about our own capabilities and others we work with. Did we achieve something because we are talented or because we got lucky? A one attempt that was successful has 100% win rate but is an underpowered analysis, we want the person who has done 100 attempts and succeeded at 75 of them.
Owning mistakes scales, it automatically makes you a leader, you are not selfish with your learning, you are sharing it, you just made others better and that makes you a leader. You showed courage, you showed that you are so confident about who you are and your abilities that you know this mistake is not representative of your skills and talents. All it represents is that you are invested in growing.
The best performing teams understand that:
“Failure is not an option*“ - Gene Kranz, NASA Flight Director on the Apollo 13 mission
*As long as:
- We own up to it
- We learn from the mistakes
- We make proportional attempts to rectify the situation
- We genuinely apologize to the parties affected
Leading Remotely
The global COVID-19 pandemic in 2020 demonstrated that remote work is a viable option, especially for certain roles. However, it’s important to note that there is no one-size-fits-all solution to the question of whether to work in a traditional co-located setting or remotely. What is clear, though, is that people value the flexibility to work remotely.
Coding is undeniably a job that can be done remotely, but software engineering is a bit more complex. Software engineering demands constant collaboration, creativity, and intense focus. Some of these activities benefit from being in the same physical location, while others benefit from the freedom to work from anywhere.
In a fully remote work environment, several challenges emerge:
- Harder to build trust
- Harder to set work-life boundaries
- Harder to collaborate
- Has psychological impact: Can be very lonely
- Has physical impact: People move considerable less when working from a home office
For companies looking to embrace remote work, it’s essential to consider these factors during the hiring process. Ideal candidates:
- Are verifiably self-disciplined
- Have other aspects to their life
- Show ability to initiate collaboration
Building trust within a team becomes a critical concern when working remotely. Research continues to highlight the significance of non-verbal communication in human interactions. We’ve evolved to pick up on subtle cues from people’s body language and facial expressions, which provide valuable insights into their emotions and thoughts about an ongoing conversation. Unfortunately, current remote technology falls short in replicating this ability.
The activities that foster familiarity and trust, such as spontaneous conversations and shared meals at the cafeteria or a nearby restaurant, play a vital role in releasing hormones that strengthen human bonds. Oxytocin, one of these key bonding hormones, is released when we engage in conversations, make eye contact, share laughter, and feel comfortable in each other’s presence. Regrettably, many of these interactions are not readily accessible in a remote work setting.
For now, the best solutions available (until we all have holodecks in our homes) include:
- Regular in-person off-sites
- Intentional Zoom/Google Meet moments
The first option can be costly, and the second one may require some skill. It’s a common feeling that after a full day of remote work, many people feel fatigued from sitting and staring at a screen. The last thing they want is to extend that experience if they can avoid it. Depending on the team’s composition, some respond well to specific virtual activities, like happy hours and show-and-tell sessions, while others prefer casual conversations sprinkled throughout their regular meetings.
Dropbox CEO Drew Houston said they use a 90/10 rule for remote work. 90% of the year on remote work, 10% on employee off-site events. “If you trust people and treat them like adults, they’ll behave like adults. Trust over surveillance”.
For people to find “remote happiness”:
- Connection with the outside
- Connection to a tribe
- Bloodflow
- Brain flow
Measuring
Alan Drexler and Sibbet, two well-renouned authors in Team Building, created the Drexler/Sibbet Performance Model. This 7-level model can be useful at narrowing down the classification of an issue within a team and how to correct the situation.
Effective Software Engineering
Software engineering is not coding. It’s the continuous team effort in designing, building, maintaining, and scaling, a software ecosystem that begins with a requirement and terminates at a utility for a user.
To know which one you are doing, ask yourself which of the following questions is the the most important in the context of what you are doing: “Does it work?” or “Is it correct?”.
Guiding Principles
- Longevity: For how long is it expected to work?
- Maintainability: How many people will be responsible for supporting it during its life expectancy?
- Criticality: What are the consequences if it fails?
- Reliability: How dependable is it in not failing?
- Upgradability: How likely is it that there is an evolution of use cases and will require updates?
- Efficiency: How does it scale with increasing user load or data volume?
- Scalability: How easily can it handle increased workloads or growing user bases?
- Security: How is the integrity and data protected?
- Usability: How user-friendly and intuitive is it for its intended audience?
- Simplicity: How can it be developed in MVC-minded (minimum viable changes) iterations?
- Accessibility: How well does it accommodate users with diverse abilities and disabilities?
Just coding can be fun and left for a quick project, a one-time use script, a repetitive enough task that could be turned into simple tooling. However, for objectives that are not inconsequential or initiatives with impact, a more rigorous approach needs to be taken.
Software engineer is also, by the above definition, a team effort, which means that different people each with specific knowledge will come together to achieve a goal. A good chunk of this handbook so far has been dedicated to how to build high-performance teams through trust and collaboration. However, the more technical aspect that needs to be covered is documentation.
Another topic that spans enough books to fill the Library of Alexandria is software design. Once a decision has been made on the objectives the software must meet (the what), tackling the design is the next step (the how). A caveat needs to be made that depending on the answers to the guiding principles, the right design now might very well not be the right design later. Unfortunately, this often leads to premature optimization, which can have disastrous consequences.
Quality
“If something is quality, it implies that there is nothing random about it” - Nicole, Human Interface at Apple
While the context of the quote is from an investigation by Apple into what makes great design, this was an answer to the broad question of “What is quality?”. Software quality can mean various things, and it can become the subject of heated debate when people try to define it around how it can be measured; however, the true identifier of software having quality, is that nothing was left to chance. All the previous questions were considered and a decision was made for them. Something could “have quality” and not have “six 9s availability” because its operational domain doesn’t require it. The critical step is that, it was considered, a decision was made, trade-offs accepted, and nothing was left to chance.
Following this definition, then the approach to guarantee high-quality software means every action and behavior that allows the software to deliver on the questions presented in the Guiding Principles. Said another way, does this piece of code deliver on its promise or is some of it random?.
Following the approach of “shift-left testing” and the mindset of “test early and often”, this promise can be verified at different stages in the software development lifecycle (SDLC) through different mechanisms, which in turn have their own ranges of relevance in the SDLC and costs. Here’s a (perhaps convoluted) way of visualizing it:
 Relative costs to fix an issue vs. time of detection vs. detection methods by cost and applicability range
Relative costs to fix an issue vs. time of detection vs. detection methods by cost and applicability range
Detection Mechanisms
- Knowledge Sharing: The earliest form of verification, before any code is written, a piece of software is just an idea or a design, but problems can still be found by ways of bringing knowledge to the table that could identify them. There are two basic forms:
- Documentation: Unless you are in the cutting edge of technology, someone already solved a similar problem. If this knowledge was recorded, then someone can consume it and by themselves find issues in their idea or design.
- Design Reviews: Bringing the knowledge sharing to a time-bound activity. Can be async or synchronously.
Static Analysis: Leveraging tools right in the development process when code is being written. Depending on the quality of the tools, this method can detect everything from syntax errors to security vulnerabilities, performance issues, and other problems that could affect the Guiding Principles.
Code Reviews: Code has been written and now other developers get involved to identify potential bugs. Logic errors, design flaws are found here and based on some edge case analysis, entire implementations can be scrapped.
- Testing: The most obvious approach, a post-fact verification with a controlled set of inputs matching the corresponding outputs. Requires code to be partially or fully completed and can either be done manually or automated.
- Manual: From proof of concept validation while the development is happening, all the way to exploratory and chaos testing once it has been released to production.
- Automatic: From unit testing, to integration testing, and acceptance and end-to-end testing.
- Monitoring: After the software is released, continuous data collection and analysis during its operation can help identify any issues experienced by users.
Documentation
“When I wrote it, only God and I knew the meaning; now God alone knows” - Johann Paul Friedrich Richter, 1826
Ask yourself the following questions:
- Have you ever complained about the lack of details, context, background, when working on something?
- How much code have you written?
- How much documentation have you written?
- How many times you’ve said “I’ll write it later”?
- How many times have you found the time?
- How many times have you forgotten about the details when you found the time?
People forget things, it is normal. Having a disciplined approach to recording valuable information as close to its moment of origin, will pay compounding dividends as team members leave or circumstances change, the organization retains critical information about its software systems. Documentation is almost as valuable as testing, but it has a delayed value effect and the immediate benefit is not for the person doing the most work, the author, but for the consumers.
Documentation comes in a variety of flavors, but it can be classified into main categories based on its main objective.
| Type | Example | Purpose |
|---|---|---|
| Technical | Code comments and code itself, API docs, technical specifications | To detail how the software works |
| Educational | Tutorials, usage guides, training materials | To teach how to use the software |
| Reference | Cheat sheets, reference manuals | To allow for quick information finding |
| Design and Architecture | System architecture diagrams, design patterns, data models | To explain design and patterns about the software |
| Operational and Maintenance | Operations manuals, runbooks, escalation policies | To define and maintainability procedures, and maintenance tasks |
| Quality Assurance | Test plans, bug reports, test reports | To define the plan and execution of testing activities, and track and manage defects |
| Legal and Compliance | Privacy policies, terms of service | To state the regulatory requirements the software must comply with |
| Project Management | Project plans, Gantt charts, status reports | To manage software projects, track progress, and communicate with stakeholders |
| Release | Release notes, changelogs | To explain changes made to software in a new release, summarize new features and functionality |
A lot of documentation becomes a mess or gets abandoned mid-way because it tries to be too many things for too many different people. When recording documentation, it’s important to consider the core characteristics of the indended audience.
- Experience Level: Experts or novices
- Experts can lose interest with many redundant background-providing explanations.
- Novices keep up more easily with explanations on each step.
- Domain Knowledge: Specialists (deep) or generalists (shallow).
- Specialists are more interested when the documentation provides something novel to them.
- Generalists tend to learn more rapidly when using analogies about similar topics.
- Discoverability Intention: Seekers or stumblers
- Seekers know what they want and need. Ease of search should be the focus.
- Stumblers don’t know what they are looking for. Clear summaries should be the focus.
The best practice for a successful knowledge sharing culture in a software organization is: to treat documentation as code. This means:
- It follows writing guidelines
- It gets reviewed for consistency, clarity, and accuracy before publishing
- It resides in source control
- It has clear ownership
- It is routinely maintained and upgraded
- It has issues opened against it, which are tracked, tested, and resolved
- It is monitored for up to date relevancy
Visualizations
“Use a picture. It’s worth a thousand words.” - Arthur Brisbane, public relations expert who coached Ford, Edison, and Rockefeller.
The important consideration is not to force data into a representation that is not is not aiding the understanding of the data. Sometimes a table is the best solution, particularly with structured and precise data.
Charts
Used to turn complex data into a format that visualizes the important takeaway. They can be sub-categorized in different ways:
- Relationship Charts: To represent correlations between variables.
- Comparison Charts: To highlight differences between values or categories.
- Distribution Charts: To show the spread of data.
- Composition Charts: To display parts of a whole.
 https://eazybi.com/blog/data-visualization-and-chart-types
https://eazybi.com/blog/data-visualization-and-chart-types
UML Diagrams
Unified Modeling Language diagrams are used for displaying structure, behavior, and interactions of software systems. They encompass various useful types like:
- Class Diagrams: For representing relationships between classes, inheritance hierarchy, attributes and methods of classes.
- State Diagrams: For representing states that an object can be in and the transitions between those states.
- Sequence Diagrams: For representing interactions between objects in a system.
- Dependency Graphs: For representing dependencies between software components.
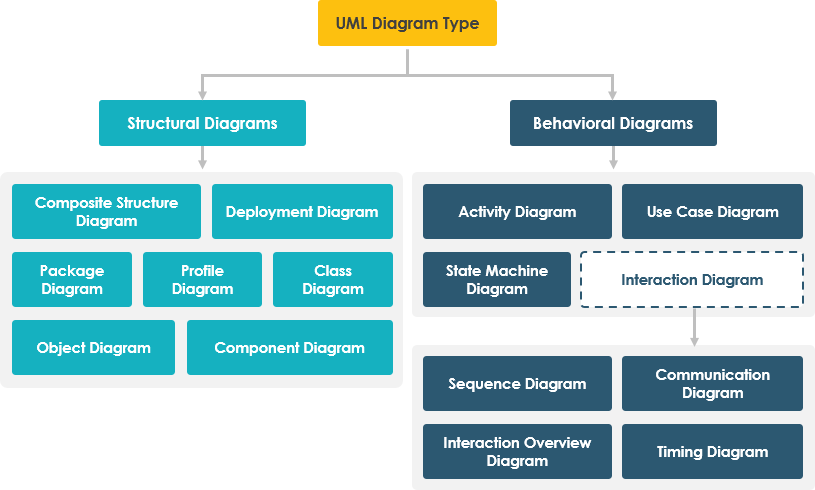
ERD Diagrams
Used for modeling and visualizing the structure of a database and its relationships between tables.
 https://docs.oracle.com/cd/A97335_02/apps.102/a81358/05_dev1.htm/
https://docs.oracle.com/cd/A97335_02/apps.102/a81358/05_dev1.htm/
Static Analysis
“Flight Controls? Check. Instrummentation? Check. Comms? Check…“ - Launch Control Center at NASA before liftoff
In aviation and spaceflight, pre-flight checklists are a standard procedure. They serve as a simple yet effective way to mitigate risks and prevent simple errors. In the world of software engineering, static analysis plays a similar role by continuously checking code as it’s being developed.
For clarification, here is a simple distinction between static and dynamic analysis:
Static analysis: Examines source code without executing the program and makes inferences about its future behavior. For example, ensuring your Apollo rocket has the right amount of fuel before launch.
Dynamic analysis: Examines the program’s behavior while it’s running. Continuing the example, this is checking rocket’s trajectory during the actual flight.
The advantages of static analysis are plenty:
- Detects bugs early in the development process.
- Enforces best coding practices.
- Prevents anti-patterns.
- Identifies potential security vulnerabilities.
- Reveals performance bottlenecks.
- Ensures code conformity across the organization.
- Helps prevent technical debt.
- Improves code readability.
To maximize the benefits of static analysis, consider the following best practices:
Part of the Build and CI Pipeline: Integrate static analysis into your build and continuous integration pipeline. This ensures that every code change is automatically analyzed for issues.
Early Integration: Implement static analysis early in the development process to catch issues as soon as possible. Integrate it with your integrated development environment (IDE), as part of code reviews, and before code is merged.
Developers Must Like It: User trust is crucial for static analysis tools. Low false-positive rates are essential, and feedback from developers helps improve the tool’s accuracy.
Evolves with the Organization: Identify domain experts and internal developers who can keep the rule sets up to date and tailored to the organization’s standards and style.
Feedback Loop: Create a feedback loop between developers and those responsible for maintaining the static analysis tooling. Encourage developers to report false positives and provide feedback to enhance the tool’s accuracy.
Meaningful Reporting: Generate meaningful reports and dashboards to provide visibility into the state of code quality and static analysis results.
Expanding on the last bullet, when gathering data about the code, static analysis can provide valuable insights by generating statistics about a codebase. These metrics offer a measure of code health, indicating how susceptible it is to breakage (brittleness) and how adaptable it is to change (inflexibility). However, this must be handled with care and careful consideration must be had on what can be infered from the metrics. For example, “code coverage” is not an accurate representation on the quality of a codebase. This topic is covered in the “Measuring” chapter →
With all this combined, there are creative ways to leverage this tooling. For example, automatically tag pre-commits with a “sensitivity score” and have custom CI pipelines for the riskier ones or going into the “unhealthier” parts of a codebase and perform a full suite of tests before merging into the repository, as opposed to a simplified suite for less sensitive commits. These approaches not only prevent code issues but also help in maintaining code health and quality.
Code Review
“Any stupid can write the program that the computer understands, but only good programmers write code that humans understand.” - Martin Fowler, author of “Refactoring: Improving the Design of Existing Code” and “Patterns of Enterprise Application Architecture.”
In the realm of effective software engineering, a rigorous and disciplined code review process is imperative. The benefits are indisputable:
- Ensures code correctness, comprehension, and consistency.
- Distributes knowledge across the organization.
- Fosters trust and relationships among team members.
- Establishes a historical record and paper trail.
The process itself is pretty straightforward:
- Every change undergoes a review before committing.
- Every engineer is responsible for initiating reviews.
- The organization or team should maintain a standardized checklist with clear expectations for reviewers and defined responsibilities for authors.
Consider implementing these guidelines from a 2006 study of code reviews at Cisco Systems, which, at the time, was the largest case study ever conducted on lightweight code review processes.
Commits should ideally consist of fewer than 200 lines of code (LOC) and must not exceed 400 LOC. Anything larger can overwhelm reviewers and result in undiscovered defects.
Reviewers should aim for a rate of reviewing 300 LOC per hour for optimal defect detection. Rates under 500 are still good, but expect to miss a significant percentage of defects if the review process is faster than that.
Authors who prepare the review with annotations and explanations tend to have far fewer defects than those who do not.
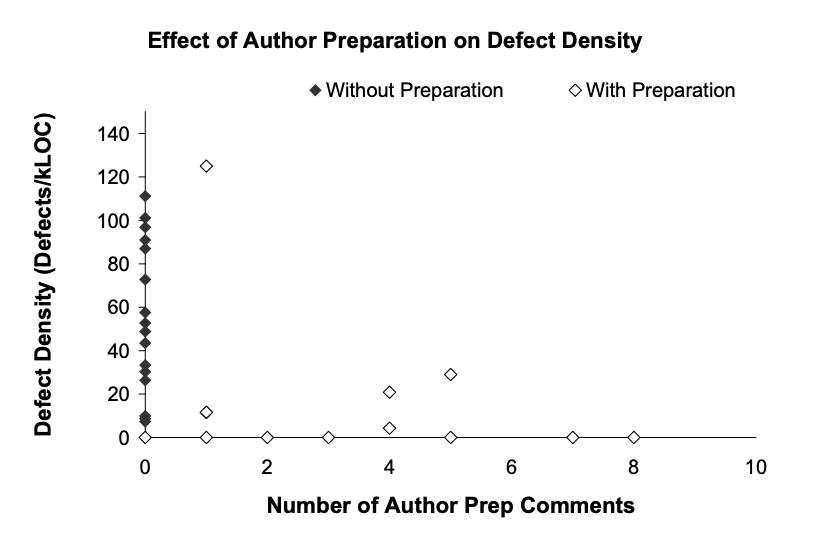
The total review time should be less than 60 minutes, and it must not exceed 90 minutes, as defect detection rates drop significantly after that time.
Reviewers’ inspection rates will naturally vary, even under similar conditions, including authors, reviewers, files, and the review’s size.
Other best practices to consider:
- Code reviews are not the time for debating previous implementation decisions.
- Prioritize consistency, readability, and maintainability over perfect efficiency. Code is read far more often than it is written.
- Make sure everyone knows that code is owned by the team, not individual engineers.
Maintain a “codeowners” file in each directory, listing the stewards for that specific section of the codebase.
- Implement a staged process for reviewing:
- Peer: Approves correctness and comprehension (LGTM) - Does it work?
- Directory owner: Approves that it adds value to the feature - Does it meet the goal without unintended consequences?
- Readability expert: Approves style and best practices - Does it align with and continues best practices?
Lastly, like any organizational process, the code review process is subject to degradation as the organization scales. Consider tracking these internal metrics to assess the health of the code review process:
- Inspection rate: Speed at which a review is performed.
- Defect rate: Number of issues found per hour of review.
- Defect density: Average number of issues found per line of code.
As with many software metrics, exercise caution when using them as a signal for performance.
Testing
“Hope is not a strategy. Luck is not a factor. Fear is not an option.” - James Cameron, Movie Director
Testing is the core action to guarantee quality. It is preventative medicine and diagnostic medicine at the same time. Every organization and team says they are quality focused and pay attention to their testing, but for many, as soon as the testing gets in the way of “delivery”, then it becomes clear that it was a second class citizen all along.
To guarantee that testing is as important as delivering, the organization needs to be ruthless in maintaining a healthy test environment. The alternative can actually be worse than having no testing at all. Slow test suites = Engineers working around the tests.
Unfortunately, variations of, “but time writing tests is time not spent on feature work”, continue to said by people who work in tech but do not understand it. The short-term gains pale in comparison to the medium and long term ones:
- Testing acts as documentation.
- Ramp up time is reduced.
- Faster code reviews.
- More efficient engineers.
- Less debugging time.
- More time spent on building rather than fixing.
- Expandability.
- Higher confidence leads to more ambitious upgrades.
A healthy testing infrastructure follows the “Pyramid Pattern” 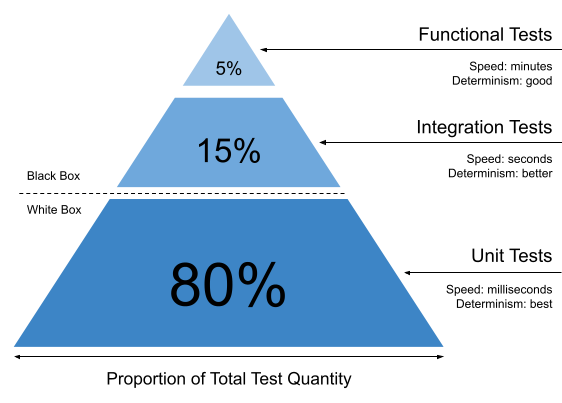 The Pyramid Pattern
The Pyramid Pattern
Best practices
- 1% flakiness means no test value.
- Test should be hermetic and not assume anything: order, database data, etc.
- Tests should avoid control flow statements like loops and conditionals.
- Tests should be deterministic and fast, and these can be at odds.
- Tests should be explicit rather than modular.
- If you care about it, put a test on it (Beyonce Rule).
- Maintainable/Non-brittle.
- Unchanging: Should only change when the requirements of the system change
- New features: shouldn’t change existing tests.
- Bug fixes: usually means a missing test case, so they add tests, not change them.
- Behavior changes: should change existing tests and add new ones.
Unit Testing
Scope: Around a single class or method.
Why they are good:
- Fast and deterministic
- Double as documentation
- Easy to write, understand, and run
- Enable rapid evolution through confidence building
Why they are not everything:
- Dependency on mocking means not a faithful representation of real-world behavior
- Blind to issues under load
- Can only test what is anticipated
Best Practices
- Tests should test only one thing
- Tests should be complete, concise, self-containing, and clear
- Tests should ideally verify state, not interactions
- Tests should be named and structured around behaviors (Given, Then, When)
- Tests shouldn’t contain logic
- Tests should have useful assertion failure messages
- Test infrastructure should have its own tests
- Follow the Four Phases of test structure (Setup, Exercise, Verify, Teardown)
Larger Testing
These are tests that are not small in scope, size, or resource cost. However, they exist because the inherent lack of fidelity in unit testing.
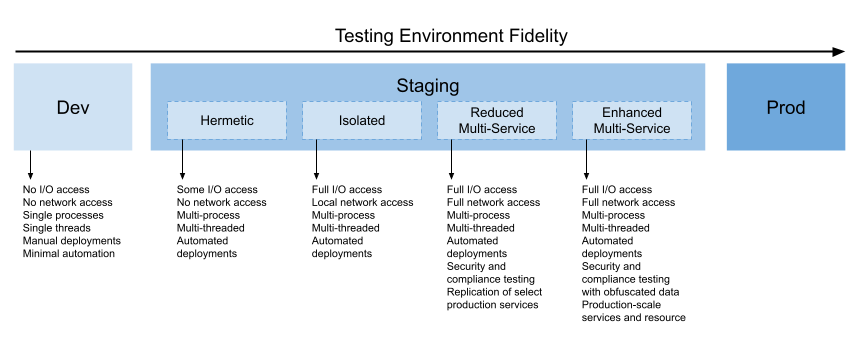
Summarized table from the Large Testing chapter of Software Engineering at Google:
| Test Type | System Under Test | Data | Verification |
|---|---|---|---|
| Functional | Hermetic system Isolated cloud | Handcrafted | Assertions |
| Browser and Device | Hermetic system Isolated cloud | Handcrafted | Assertions |
| Performance, Load, and Stress | Isolated cloud | Handcrafted Copy of production | Delta from baseline Threshold |
| Deployment Configuration | Hermetic system Isolated cloud | None | Successful start |
| Exploratory | Production env Staging env | Copy of production Handcradfted | Manual |
| A/B Diff Regression | Two envs | Copy of production | Diff comparison |
| User Acceptance Testing | Hermetic system Isolated cloud | Handcrafted | Assertions |
| Probers and Canary | Production env | Production | Delta from baseline |
| Chaos Engineering | Production env | Production | Manual |
| User Evaluation | Production env | Production | Manual |
Technical Debt
 - Martin Fowler on Technical Debt
- Martin Fowler on Technical Debt
Software systems, over time, tend to accumulate what has been labeled “technical debt.” This term describes the deficiencies in the internal quality of a software system that make it more challenging than it should, to modify and extend the system further. The metaphor of “technical debt” compares these deficiencies to financial debt.
The extra effort required to add new features or make improvements represents the interest paid on the technical debt.
Coined by Ward Cunningham, the metaphor sheds light on the idea that taking shortcuts in your software development process has long-term consequences. Just as with financial debt, where borrowing money incurs an interest cost, taking shortcuts in software development today means paying a price with interest later. For instance, introducing a global variable to save time in the short term might lead to spending more than that saved time on fixing issues down the line.
Impact
A high level of technical debt in the codebase translates into a slow delivery of new features. This is a very common source of frustration and can lead to difficult conversations about the system’s capability to support business needs. However, developers are the ones that truly feel the impact of technical debt. The reduced productivity and working around constraints that they know should be fixed can be extremely frustrating. If left unchecked for long enough, talented and sought after engineers will jump ship into organizations that invest in paying off their debt. Not only is the frustration on an individual level, it often leads to conflicts within the team. Usually in the form of disagreements about the best approach to address the mounting technical debt or to work around it.
How to Improve
Recognizing and feeling technical debt is one thing; effectively managing it is another. To address it, teams must allocate time and resources to deal with it proactively:
Dedicate Capacity: Without a dedicated effort, it will never be addressed. Establish a regular cadence for the team to allocate time to tackle technical debt issues. Delaying this work only makes the situation worse.
Integrate with Regular Work: Track technical debt items alongside other work items (such as user stories or tasks). Ensure that a portion of your team’s effort is directed towards addressing technical debt, perhaps making it a part of every sprint.
Scheduled Technical Debt Days: Designate one day every week for addressing technical debt issues. For a standard five-day workweek, this equates to a minimum of 20% of your development capacity dedicated to addressing debt.
Rotating Role: Implement a rotating role within the development team, where assigned developers work exclusively on addressing technical debt for a set period.
Prevent New Debt: In addition to addressing existing technical debt, teams should actively work to prevent incurring new debt. This involves careful code practices and refactoring as an integral part of feature development.
Managing Debt
There’s a common misconception that all technical debt is detrimental and should be avoided at all costs. Just as in the world of financial debt, not all debt is created equal. Taking on manageable technical debt for strategic reasons can be a sound decision. The key is to understand the type of debt being incurred and its interest rate, which, in the context of technical debt, is the time spent addressing it.
As it happens often, stakeholders may resist addressing technical debt due to various reasons. If full buy-in is challenging to obtain, there are some modest steps you can take:
- Quantify and Visualize Impact: Create a dashboard or table that easily shows the areas of the code where the debt hasn’t been paid. Utilize this dashboard in early feature and design conversations and record how often the business is paying the price of not correcting the issues.
- Identify Debt Upfront: When you anticipate technical debt in a project, create a ticket for it in your project-management tool. Estimate its level of effort, treating it like any other project item.
- Use Windfalls: If a project is completed ahead of schedule, allocate the extra time to pay down technical debt, effectively reducing the interest on that debt.
- Emphasize Opportunities: Make stakeholders aware of the benefits of addressing technical debt. By investing a short amount of time in resolving tech debt items, you can unlock opportunities for critical business functions to scale and perform more effectively.
CI/CD
“Besides black art, there is only automation and mechanization.” - Federico García Lorca, Spanish poet and playwright.
CI/CD is a fundamental practice in modern software development. It accelerates software delivery, enhances quality, and minimizes the time between code changes and user accessibility. Here’s a comprehensive CI/CD pipeline with multiple various stages, ensuring code quality, security, and reliability:
Push Commit: Developers commit their code changes.
Build Binaries: Code is compiled into executable binaries.
Run Static Analyzers (Linters): Static analyzers check code for issues and compliance with coding standards.
Run Unit Tests: Testing individual code components.
Run Security Checks: Identifying and mitigating vulnerabilities.
Publish Generated Artifacts to Storage: Storing build artifacts for later stages.
Build Container Images and Publish to Container Registry: Preparing container images for deployment.
Perform Integration Tests: These tests check how different parts of your application interact with each other, ensuring that they work together seamlessly.
Deploy to Staging Environment: After building and testing, deploying the application to a staging environment for comprehensive testing that closely resembles the production environment.
Perform Full Testing: Check the functionality and behavior of the entire application, simulating real-world scenarios, how it performs under various loads, check with stakeholders and ensure it meets requirements and expectations.
Release Approval: A manual or automated step to ensure that the application is ready for production deployment, with checks for compliance and quality.
Deploy to Production Environment: Consider following safe strategies for deploying new versions of the application to production, where you can gradually shift user traffic to the new version for monitoring and rollback if issues arise.
Zero-Downtime Deployments: CI/CD pinnacle where updates are seamlessly rolled out, leaving users unaffected. Achieved through orchestration and rigorous testing, exemplifying pipeline resiliency.
Test Strategies
- Pre-Submit Testing: Swift, high-signal tests for pre-submit commits uphold code quality during development.
- Post-Submit Testing: Comprehensive tests post-submit offer enhanced codebase confidence.
- Staging Testing: Thorough testing in a staging environment, ahead of production deployment, ensures validation of critical scenarios.
- Production Testing: Running a complete test suite against the production environment guarantees the final, correct code state.
- Representative Testing: When comprehensive testing is not possible, go for select representative scenarios to gain valuable insights.
Deployment Strategies
- Incremental Rollouts and Canary Deployments: To minimize risk and gather rapid feedback, consider incremental rollouts. Deploy updates to a small subset of users initially before full distribution, allowing for early issue detection and user-focused changes.
- Experiments and Flag-Guarding: They reduce deployment risk by isolating changes within modular components that can be dynamically toggled in production.
- Automated A/B Releases: Automate A/B testing in the CI/CD pipeline for controlled comparisons.
- Fast Automatic Rollbacks: Rapid, automated rollbacks in case of issues maintain software reliability.
Other Best Pratices
Implementing CI/CD for Infrastructure as Code (IaC): Extending CI/CD principles to Infrastructure as Code (IaC) automates infrastructure provisioning and management, ensuring consistency and reliability. This practice minimizes misconfigurations and enhances deployment efficiency.
Zero-Downtime Deployments: Zero-downtime deployments exemplify CI/CD excellence. They involve seamless updates without disrupting users, achieved through meticulous orchestration and rigorous testing. This demonstrates the resiliency of your CI/CD pipeline.
Immutable Infrastructure and Blue-Green Deployments: Treating infrastructure as code and using blue-green deployments offer consistent environments and swift rollbacks in case of issues. These practices boost the resilience of your CI/CD pipeline.
Configuration as Code: Managing application configurations as code ensures version control, auditability, and consistency across environments. It streamlines deployment and mitigates misconfiguration risks that can lead to operational issues.
GitOps: A progressive approach within CI/CD, GitOps, manages the entire pipeline through version-controlled Git repositories. This simplifies deployment and configuration management, offering consistency and auditability.
Like pretty much every aspect of software engineering, to maintain a robust CI/CD pipeline, it’s crucial to invest in observability and monitoring tools. These tools provide real-time insights into the pipeline’s health and performance. Monitoring key metrics and setting up alerts allows organizations to detect and address issues proactively, ensuring consistent delivery of reliable, high-performance software.
Productivity & Performance
“The customer doesn’t care about story points, they care about quality of the features they need.”
Reducing the intricate art of software engineering to mere code generation through the use of story points oversimplifies the process. While story points play a valuable role in project management, it’s important to remember that engineers are motivated by what rewards them. Ultimately, the end customer’s concern lies not in points but in the quality of the features they rely on.
When it comes to metrics, while velocity is important, it takes a back seat to the concepts of acceleration and deacceleration. Once a baseline is established for a team or an individual, changes in these metrics can reveal underlying issues and offer valuable insights.
From a 2019 study on Engineering Productivity by Google:
“Our results suggest that the factors that most strongly correlate with self-rated productivity were non-technical factors, such as job enthusiasm, peer support for new ideas, and receiving useful feedback about job performance. Compared to other knowledge workers, our results also suggest that software developers’ self-rated productivity is more strongly related to task variety and ability to work remotely.”
Furthermore, Google’s Productivity Research team found that many organizations forget core trade-offs when trying to measure engineering output. They become focused on velocity and forget to measure quality (or vice versa). The team concluded that productivity can be decomposed into five core components. These five components are in trade-off with one another, and should be considered together. They used the mnemonic “QUANTS”:
Quality of the code
- What is the quality of the code produced?
- Are the test cases good enough to prevent regressions?
- How good is an architecture at mitigating risk and changes?
Attention from engineers
- How frequently do engineers reach a state of flow?
- How much are they distracted by notifications?
- Does a tool encourage engineers to context switch?
Intellectual complexity
- How much cognitive load is required to complete a task?
What is the inherent complexity of the problem being solved? Do engineers need to deal with unnecessary complexity?
Tempo and velocity
- How quickly can engineers accomplish their tasks?
- How fast can they push their releases out?
- How many tasks do they complete in a given timeframe?
Satisfaction
- How happy are engineers with their tools?
- How well does a tool meet engineers’ needs?
- How satisfied are they with their work and their end product?
- Are engineers feeling burned out?
So, what are strategies to measure productivity? They can be
Qualitative:
- Quarterly surveys
- On tools, processes, and activities. Use Goals Signals Metrics framework
- Realtime feedback
Quantitative:
- Ingests logs from dev tools
- Captures sessions to view dev workflows such as code reviews
- Captures metrics such as coding time, reviewing time, email time, meeting time
Do not use productivity metrics as performance reviews. Don’t measure productivity of individuals, measure the aggregate productivity of a team.
Effective Software Architectures
A constantly evolving topic, however, these are the most common (non-mutually exclusive) architectural patterns:
- Monolithic
- Service-Oriented / Microservices
- N-Tier
- Web-Worker-Queue
- Serverless
- Containerized & Orchestrated
- Event-Driven
- Multitenancy
- API-First
- Jamstack
- Headless CMS
- Progressive Web App
Each of these architectural patterns has its own unique implementations. The challenge lies in choosing the right one early in your project’s lifecycle to ensure long-term success. As this landscape keeps evolving, it’s wise to keep your options open for future changes.
| Pattern | Benefits | Challenges | Use When | Do Not Use When |
|---|---|---|---|---|
| Monolithic | Simplicity during development and deployment. Efficient communication between components. | Scaling can be challenging since the entire application is scaled as a single unit. Codebase can become complex and hard to maintain as the application grows. | Smaller projects with straightforward requirements. Rapid development and prototyping. | Large, complex applications requiring extensive scalability and flexibility. Projects with diverse technology stacks. |
| Service Oriented, Micro-services | Scalability and flexibility for large, complex applications. Technology and language agnosticism. | Complexity in managing and coordinating multiple services. Potential latency in communication between services. | Large, complex applications with varying workloads. Teams with expertise in specific domains. | Smaller projects with limited scalability needs. Projects with tight development timelines. |
| N-Tier | Separation of concerns and maintainability. Scalability at specific tiers. | Complexity in managing multiple tiers and dependencies. Tight coupling between layers. | Enterprise-level applications with clear separation of concerns. Projects requiring a structured and maintainable architecture. | Small projects where the added complexity may outweigh the benefits. |
| Web-Worker-Queue | Efficient handling of background tasks and asynchronous processing. Scalability and fault tolerance. | Management and coordination of worker processes. Ensuring data consistency and handling failures. | Applications with resource-intensive or time-consuming tasks. Scalable backends with real-time features. | Simple applications with minimal background processing. |
| Serverless | No infrastructure management. Auto-scaling and cost-efficiency. | Limited control over infrastructure. Potential cold start latency in serverless functions. | Event-driven, stateless functions. Backend for mobile and web apps. | Long-running or resource-intensive processes. |
| Containerized & Orchestrated | Portability and consistency in deployment. Scalability and orchestration of containers. | Complexity in container management and orchestration. Resource utilization and cost monitoring. | Microservices architectures. Applications that need to run consistently across different environments. | Simple applications with low resource requirements. |
| Multitenancy | Independent scaling and customization for each tenant. Shared management and resources reduce complexity and costs. | Data isolation and securing access between tenants. Performance consistency across the individual requirements. | SaaS organizations providing software to multiple customers. E-Commerce platforms hosting multiple online stores. | Low or single tenancy count. Tenants requiring extensive customization. |
| Event-Driven | Loose coupling of components. Real-time data processing and responsiveness. | Event propagation and message processing. Ensuring event order and delivery. | Real-time data processing, IoT, and event-driven applications. Systems requiring decoupled components. | Simple, single-purpose applications. |
| API-First | Clear and consistent API design. Promotes reusability and integration. | Ensuring consistent and discoverable APIs. Managing versioning and documentation. | Projects that require public or internal APIs. Microservices with external interfaces. | Internal, small-scale applications with no API exposure. |
| Jamstack | Fast and secure web experiences. Simplified deployment and scaling. | Requires specialized tools for building and deploying. Not suitable for dynamic content and applications. | Content-driven websites and blogs. Sites with low interactivity and dynamic content needs. | Complex web applications with heavy client-side logic. |
| Headless CMS | Separation of content management from presentation. Flexibility and ease of content delivery. | Integration with the frontend and maintenance. Learning curve for headless CMS usage. | Content-rich websites and applications. Projects requiring multisite content management. | Simple static websites or single-page applications. |
| Progressive Web App | Enhanced user experience with offline access and speed. Improved engagement and conversion rates. | Requires advanced frontend development skills. May not be suitable for all types of applications. | Consumer-facing web applications, e-commerce, news sites. Projects where mobile and web experiences should be consistent. | Internal tools or enterprise applications. |
Components
A summary of common components and services used in most software architectures. Most of these have the corresponding AWS product with their definition.
Servers
Web Servers: These servers handle incoming HTTP requests from clients, serve web pages, and may perform some initial processing.
Application Servers: These servers execute the core business logic and process more complex operations beyond serving web pages (EC2).
Caching Servers: Caching servers like Redis or Memcached are used to store frequently accessed data in memory for faster retrieval (ElastiCache)
Proxy Servers: Proxy servers sit between clients and other servers, serving as intermediaries to handle requests, improve security, or act as gateways to internal services.
Load Balancers: Load balancers distribute incoming traffic across multiple web or application server instances to ensure even load distribution and high availability (Elastic Load Balancer)
Content Delivery Networks: CDNs distribute content to geographically distributed servers, reducing latency and improving content delivery (CloudFront).
Network Appliances: VPCs, Subnets, Internet/NAT Gateways, etc
Data Storage and Retrieval Services
Fundamental components that allow storing, managing, and accessing different types of data, structured in different formats to optimize for a wide array of operations and use cases.
Relational Databases: Relational databases are a type of structured data storage system that organizes data into tables with predefined schemas. They use Structured Query Language (SQL) for their operations. (RDS, Aurora)
NoSQL Databases: Non-relational databases designed to handle semi-structured data, offering flexibility in data modeling. They are typically in the form of key-value pairs (XML, JSON) for their operations. (DynamoDB)
NewSQL Databases: A class of relational database management systems that combine the scalability of NoSQL systems with the ACID guarantees of a traditional database system.
In-Memory Databases: Data stored in RAM for extremely fast data retrieval at the expense of persistence. Mostly used for caching services, optimizing frequently accessed data to reduce the load on primary data storage. (ElastiCache)
Data Lakes: Storage repositories that can hold vast amounts of data of all types, structured, semi-structured, but particularly for raw, unstructured data such as text files, images, audio, video, etc. (S3)
Data Warehouses: Databases used for storing and analyzing large volumes of structured data. (Redshift)
Messaging Services
These services are the backbone of communication in distributed systems, enabling the exchange of data between components and facilitating various messaging scenarios. They come in different flavors, each tailored to specific use cases.
Message Queues (SQS): Designed for ensuring the successful delivery and processing of messages, emphasizing individual client interactions. They are suited for scenarios where maintaining message order is critical and basic queuing functionality suffices. Message Queues guarantee message order, making them suitable for managing tasks in background job processing systems.
Message Brokers (MQ): More feature-rich queues providing routing, message transformation, and protocol mediation. They excel in orchestrating complex messaging scenarios and are ideal for systems with multiple interconnected components that need to exchange data in flexible ways. With routing and message transformation capabilities, Message Brokers provide sophisticated message handling for various data formats and protocols.
Event Brokers (SNS, EventBridge): They focus on message delivery in an event-driven architecture, broadcasting the same message to multiple recipients. They promote loose coupling between components by using a publish-subscribe model, where events are published to specific topics, and subscribers express interest in particular topics. Event Brokers are best suited for scenarios demanding real-time data sharing, event-driven programming, and service decoupling, making them a vital component in microservices architectures and applications requiring real-time updates.
Containers and Orchestration Services
Containerizing (A2C), Container Registries (ECR), Container Orchestration (ECS, EKS).
Microservices and Serverless Services
API Gateways, Event-Driven Computing (Lambda), Authentication and Authorization Services (Cognito).
Monitoring and Logging Services
Tools for tracking system performance and diagnosing issues (CloudTrail, CloudWatch).
Specialized Services
Application Management (ElasticBeanstalk), Identity and Access Management (IAM), Secret Handlers, Search Engines (OpenSearch), Business Intelligence (QuickSight), Analytics Tools (Athena, Kinesis)
Practices
This is an attempt at organizing a “cheat sheet” of an ever-evolving number of practices that are important to know when designing software architectures.
Architectural & Development Patterns
- 12 Factors: A set of guidelines for building cloud-native applications with a focus on scalability, resilience, and maintainability.
- Serverless Computing: Understanding serverless architecture and its benefits, such as automatic scaling and reduced operational overhead.
- Microservices Architecture: Designing software as a collection of small, independent services that can be developed, deployed, and scaled independently.
- Immutable Infrastructure: Extending the concept of immutable infrastructure to application code and configuration, not just infrastructure components.
- Chaos Engineering: Testing and improving a system’s resilience by intentionally injecting failures and monitoring its behavior.
- Containerization and Orchestration: Understanding container technologies like Docker and container orchestration tools like Kubernetes. These are crucial for managing and deploying applications in a containerized environment.
- API-First Design: Developing APIs as a core part of the system’s architecture and design.
- Domain-Driven Design: Structuring software around specific business domains for better organization and understanding.
- CQRS (Command Query Responsibility Segregation): Separating the data modification (command) and data retrieval (query) parts of an application for improved scalability and performance.
- Event Sourcing: Storing data as a series of immutable events for maintaining a full history of changes.
- Reactive Programming: Building systems that react to data changes, enabling real-time functionality.
- Infrastructure as Code (IaC): Leveraging IaC tools like Terraform or AWS CloudFormation to manage and provision infrastructure programmatically.
Scalability and Performance
- Autoscaling: Automatically adjusting resource allocation to handle varying workloads and traffic.
- Caching: Storing frequently accessed data in memory for faster retrieval and reduced load on databases.
- Content Delivery Networks (CDNs): Distributing content to geographically dispersed servers for lower latency and faster content delivery.
- Data Partitioning: Dividing data into smaller parts to improve performance and manageability.
- Database Sharding: Horizontal partitioning of databases to distribute data across multiple servers for scalability.
- Load Balancing: Distributing incoming network traffic across multiple servers or resources to ensure high availability.
- Database Indexing: Enhancing database query performance by creating efficient indexes.
- Amortization: Spreading the cost of an operation over time to reduce immediate impact.
- Batch Processing: Processing data in large batches for efficiency.
- Vertical Scaling: Increasing the capacity of a single server by adding more resources (e.g., RAM, CPU).
- Horizontal Scaling: Adding more servers to distribute the workload and improve system performance.
Resilience and Reliability
- Monitoring: Implementing tools and practices for real-time system health checks and performance tracking.
- Retry Mechanisms: Strategies for handling transient failures by automatically retrying operations.
- Log Aggregation: Collecting and analyzing log data from multiple sources for debugging and monitoring.
- Redundancy and Failover: Ensuring system availability by duplicating critical components.
- Circuit Breakers: Preventing excessive traffic to a failing service to maintain overall system stability.
- Fallbacks: Providing alternative responses or mechanisms when primary functionality fails.
- Timeouts: Specifying maximum allowable time for an operation to prevent indefinite waiting.
- Idempotence: Ensuring that an operation can be repeated multiple times with the same result.
- Versioning: Managing changes in data and APIs to maintain backward compatibility.
- Immutable Infrastructure: Treating infrastructure components as immutable, making updates by replacing rather than modifying.
- Service Mesh: Implementing a service mesh (e.g., Istio) for enhancing the resilience and observability of microservices-based architectures.
Security
- Secret Handling: Secure storage and management of sensitive data like API keys and credentials.
- Firewalls and Intrusion Detection/Prevention Systems: Protecting systems from unauthorized access and threats.
- Security Protocols: Implementing secure communication protocols like SSL/TLS.
- Vulnerability Scanning: Regularly assessing and patching security vulnerabilities in software and dependencies.
- Authentication and Authorization: Verifying user identity and defining what actions they can perform.
- Data Encryption: Protecting data by converting it into a secure format that requires decryption to be read.
- Input Validation: Ensuring that input data is safe and does not introduce security vulnerabilities.
- Output Encoding: Encoding output to prevent cross-site scripting (XSS) attacks.
- Content Security Policy (CSP): Defining and enforcing policies to mitigate security risks in web applications.
- Cross-Site Request Forgery (CSRF) Protection: Implementing measures to prevent CSRF attacks.
- API Security: Enhancing API security with practices like OAuth, JWT, and API rate limiting.
- Data Privacy and Compliance: Understanding data privacy regulations (e.g., GDPR, CCPA) and how they impact software architecture and data handling.
Database Optimization
- Query Optimization: Techniques for improving database query performance.
- Denormalization: Storing redundant data to reduce complex joins and speed up queries.
- Database Replication: Creating copies of a database to improve data availability and redundancy.
- Database Version Control: Managing database schema changes and migrations.
- ACID Transactions: Ensuring the reliability of database transactions.
- Schema Design: Structuring database schemas for efficiency and data integrity.
- Indexes: Creating efficient indexes for faster data retrieval.
- Scalable Databases: Exploring scalable database technologies, such as NewSQL databases, that are designed for high scalability and performance.
Data Processing
- MapReduce: A programming model and data processing technique for distributed and parallel processing of large datasets. It’s particularly useful for tasks that can be divided into “map” and “reduce” phases, providing scalability and performance improvements.
- ETL (Extract, Transform, Load): ETL processes involve extracting data from various sources, transforming it to fit the target schema, and loading it into a data store or data warehouse. ETL is crucial for data integration and analysis.
- Stream Processing: Stream processing frameworks like Apache Kafka and Apache Flink enable real-time data processing and analytics. They’re used in scenarios where low-latency data analysis is required.
- Data Migration: Data migration strategies and tools are essential for moving data between systems, such as when transitioning to a new database or cloud platform.
- Data Warehousing: Understanding data warehousing concepts for large-scale data analysis and reporting.
- OLTP: Online Transaction Processing is a type of data processing that consists of executing a number of transactions occurring concurrently.
Tenancy and Multitenancy
- Multitenancy: Designing applications to serve multiple tenants or customers from a single instance.
- Isolation: Ensuring the separation and security of tenant data.
- Data Security: Implementing measures to protect tenant data.
- Performance Optimization: Optimizing the system to provide consistent performance for all tenants.
Development and Operations
- DevOps Practices: Incorporating DevOps principles and practices, including continuous integration, continuous deployment (CI/CD), and automation of software development and operations processes.
Networking
- Public/Private Subnet Connectivity: Managing network access and security within subnets.
- Content Distribution: Efficiently distributing large files or content across multiple servers.
- CDN Integration: Integrating Content Delivery Networks for faster content delivery.
- API Gateways: Managing and securing APIs for external access.
- Reverse Proxies: Acting as intermediaries between clients and servers for load balancing and security.
- Load Balancers: Distributing network traffic for high availability and fault tolerance.
- DNS: Resolving domain names to IP addresses for network communication.
- Service Discovery: Automatically locating and connecting to services in a network.
Internationalization
- Internationalization and Localization: If your software has a global audience, consider the challenges and practices for internationalization and localization.
Optimizations
“Prematurely optimizing small efficiencies is usually the root of all evil; prematurely optimizing large efficiencies is a necessity.” - Donald Knuth, the informal Nobel Prize winner of computer science.
Every software product has to fulfill a utility, they don’t just exist as art installations. Depending on what the product or service is designed to achieve, there are a few core improvements that can be made to maximize the providing of said utility to the end user:
- Performance
- Scalability
- Maintenability
- Resiliency/Availability
- Security
- Cost
However, there is a delicate balance on when to pursue any of these optimizations. Doing so too far in advance can be wasteful and disastrous. There are steep learning curves, the handling of the extra complexity can have a considerable negative impact on a small startup, and most importantly, the cost could easy put a young organization out of business. Consider the 3X Approach in the Success Chapter of Effective Organization. Don’t focus on these if you are exploring, identify which optimizations matter to you if you are expanding, and invest and focus on these if you are extracting.
References
As stated at the beginning, this book is an amalgamation of my own practices, principles, and opinions, with others I’ve learned from others. Where applicable, I link directly to the source material that I’m either directly referencing or paraphrasing. However, there may be places where I took note once and didn’t record the origin. So, here’s a list of books, blogs, articles, pages, videos, and more, that I’ve consumed in my career and have in one way or another informed and shaped my approach to software engineering, leadership, and engineering leadership. In no particular order:
- Built to Last
- Software Engineering at Google - Tom Manshreck & Hyrum Wright
- The Mythical Man-Month - Fred Brooks
- Peopleware: Productive Projects and Teams - DeMarco, Lister
- Leaders Eat Last - Simon Sink
- Drive: The Surprising Truth about what motivates us - Dan Pink
- Thinking Fast and Slow
- The 15 Commitments of Concious Leadership - Diana Chapman
- Nonviolent Communication: A Language - Marshall Rosenberg
- Who - Geoff Smart
- Principles: Life and Work - Ray Dalio
- Getting things Done - David Allen
- One Minute Manager - Ken Blanchard
- High Output Management - Andy Grove
- The Hard Things about Hard Things - Ben Horowitz
- Disciplined Entrepreneurship - Bill Aulet
- Never Split the Difference - Chris Voss
- The Courage to be Disliked - Ichiro Kishimi and Fumitake Koga
- The Great CEO Within - Matt Mochary and Alex MacCaw
- Crucial Conversations - Kerry Patterson
- Principles: Life and Work
- Super Thinking: The Big Book of Mental Models
- https://martinfowler.com/
- https://handbook.gitlab.com/
- https://themanagershandbook.com/